
«Täderlät» die KI?
Vor ein paar Wochen fragte mich jemand besorgt, ob man denn gar nichts in Chatbot-Fenster eingeben könne, was man nicht auch öffentlich teilen würde. Während der Erklärung fiel mir auf, dass ganz viele Leute ganz wenig Ahnung haben, wie die Datenflüsse bei KI-Chatbots wie ChatGPT etc. eigentlich ablaufen.
Deshalb habe ich für euch (und alle, die mit KI liebäugeln) das mal aufgeschrieben und aufgezeichnet.
Dies ist ein Zusammenzug aus zwei DNIP-Artikeln: «KI zwischen Genie und Wahnsinn: Fehler und ihre Elimination in Chatbots» und «Petzt die KI? Schlimm?». Mehr und ausführlichere Informationen finden sich dort. (Der «Fehler»-Artikel ist übrigens eine erweiterte Version des hier erschienen «KI-Datenkreisläufe»-Artikels.
Sprach-KI vor 2017 — und ihre Mängel
Lasst mich zuerst einmal etwas ausholen:
Vor 2017 (und hinter dem Schatten der LLM wie ChatGPT) hat man versucht, Sätze zu analysieren und in Subjekt, Verb, Objekt aufzuteilen. Das war furchtbar ineffizient (aus Sicht des Programmieraufwands).
«Modern» macht man das nicht mehr, sondern nutzt nur noch Statistiken über weite Teile des Internet: Alle Texte, die Menschen so geschrieben haben. Da nimmt man als KI-Firma dann alles, was man so in die Finger bekommt.
Chatbots heute — und ihre Fehler
Heutige KI-Chatbots funktionieren nach einer einfachen — dafür extrem daten- und rechenintensiven — Methode:
Texte aus dem Internet werden in Statistiken verwandelt und aus diesen wieder Texte generiert, die diesen Statistik-Mustern entsprechen.

Dabei können natürlich alle möglichen Fehler passieren: Ironie wird oft nicht als solche erkannt oder es wird bei der Generierung der Antwort das falsche Statistik-Muster angewandt. Beispielsweise das Dreisatz-Muster, wenn es nicht gilt, wie beispielsweise bei (Teil-)Schwangerschaften.
Diese Blamagen durch Fehler wollen die KI-Konzerne nicht auf sich sitzen lassen. Das bedeutet: Nachsitzen für den Chatbot, noch mehr Training.
KI-Chatbots sind aber langsam im Lernen: Sie brauchen ein Vielfaches des Inputs, den ein Kind dafür benötigen würde, bis sie das endlich verinnerlicht haben. Also werden möglichst viele Trainingsdaten gebraucht. Und dann noch weitere, unabhängige, Testdaten, um zu verifizieren , dass das Training auch erfolgreich war.
Da schon fast das gesamte Internet abgegrast ist, suchen die KI-Firmen nach mehr Trainings- und Testdaten, welche den Fehler aufzeigen. Was gäbe es da besseres, als die Chatverläufe der eigenen Nutzer:innen? Diese User:innen haben sicher mit den Fehlern herumexperimentiert:
- Wann schlägt ChatGPT vor, dass sich doch auch 9 Frauen eine Schwangerschaft teilen können? Wie bringt man ChatGPT dazu, das auch noch zu sagen, nachdem der Hersteller glaubt, dass das Problem behoben sei?
- Wann schlägt Gemini vor, den Pizzabelag mit Leim festzukleben? Wie bringt man Gemini dazu, das zuverlässig zu sagen?
Genau sowas wären doch die perfekten Testdaten!

Also haben sich die KI-Firmen das Recht ausbedungen, die Chatverläufe analysieren und nutzen zu dürfen.
All‘ das und noch viel mehr im DNIP-Artikel, wie die KI-Trainingsschleifen und -Datenverarbeitungen funktionieren.
Learning lessons learned
Wenn man weiss, wie mit den Daten umgegangen wird und wie Fehler entstehen, fällt es einem leichter, sich an folgenden Regeln zu halten:
- Die 80%-Regel: Traue den Antworten des Chatbot|s nur so weit, wie du dich auch fast auskennst.
- Nutze sie nicht ungeprüft für Automatisierungen, die Schaden anrichten oder peinlich ausgehen können. Also kein Automated Decision Making (ADM).
«Täderlä», petzen, ausquatschen, …
Mit diesem Wissen um die Datenflüsse rund ums KI-Training können wir nun auch die Frage beantworten: Ob, wann und wie können meine Eingaben an einen Chatbot dann an anderen Stellen auftauchen?
Auch hier gibt es mehrere Möglichkeiten:
0. Der Mensch
Zuerst einmal die menschliche Komponente: Durch die Interaktionsfähigkeit und den „menschlichen“ Touch des Dialogs, sind wir freigiebiger mit Informationen als bei einer Google-/Wikipediasuche.
1. Die Cloud
Auch ein KI-Dienst ist ein Online-, genauer, Cloud-Dienst. Da gelten die normalen Gründe und Risiken:
- Unser eigener Rechner bzw. unser Konto kann gehackt werden. Da gelten die üblichen Vorsichtsmassnahmen wie gute, eindeutige Passwörter (in einem Passwortmanager!) und Aktivierung der Zwei-Faktor-Authentisierung
- … sowie das Vertrauen in den Cloudanbieter, dass er das mit Datenschutz und Datensicherheit ernst meint.
Leider ist das sehr schwer von aussen zu beurteilen. Für Normalsterbliche meist erst, *nachdem* der Anbieter gehackt wurde. Und dann ist es auch zu spät.
Da bleibt (für Normalsterbliche) kaum mehr als Hoffnung, dass zumindest etablierte Firmen das im Griff haben. (Aber auch das ist keine zuverlässige Regel.)
Zurück aber zu den KI-spezifischen Risiken:
2. Risiken aus der KI selbst
Im Normalfall bleiben alle Informationen innerhalb eines Chatverlauf|s. Es gibt aber Ausnahmen, wie die neuen Memory-Funktionen und eben die oben bereits angesprochene Nutzung der Chats als Trainings- oder Testdaten.
Ja, es gibt Möglichkeiten, *gewisse* Trainingsdaten 1:1 wieder als Antwort zu erhalten. Aber damit ist es (bisher, und vermutlich auch zukünftig) nicht möglich, gezielt unbekannte Daten auszuforschen.

Ja, es besteht die Möglichkeit, dass vielleicht irgendwann Bruchstücke aus einem deiner Chatverläufe woanders auftauchen können. Aber das kann auch Zufall sein, also, dass der Output auch entstanden wäre, ohne dass das in deinem Chatverlauf gestanden hätte.
Und das dürfte wohl auch weiterhin der Standard sein. Details im Artikel.
Tipps
Aber man muss sein Glück nicht herausfordern. Deshalb schliesst der Artikel mit ein paar Tipps:
- Eigenen Rechner/Konto schützen
- Grundsätzlich Vorsicht bei der Eingabe von schützenswerten Daten
- Eingaben anonymisieren (also nicht: „Schreibe eine fristlose Kündigung für Herrn Meier, der X gemacht hat“)
- Wenn man kritische Daten verarbeitet, auf einen Provider/Vertrag wechseln, bei dem die Chatdaten nicht verwendet werden. Oder Häkchen setzen.
Happy KI!
Künstliche Intelligenz
News (mehr…)
- «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich
 Forschende der Uni Zürich haben KI-Bots in ein Forum der Plattform Reddit eingeschleust. Und zwar ohne Wissen der Betreiber:innen und… «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich weiterlesen
Forschende der Uni Zürich haben KI-Bots in ein Forum der Plattform Reddit eingeschleust. Und zwar ohne Wissen der Betreiber:innen und… «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich weiterlesen - Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView»
 Wie DNIP.ch am Montag als erstes Medium berichtete, hat eine Forschungsgruppe mit Anbindung zur Universität Zürich mittels KI psychologische Forschung… Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView» weiterlesen
Wie DNIP.ch am Montag als erstes Medium berichtete, hat eine Forschungsgruppe mit Anbindung zur Universität Zürich mittels KI psychologische Forschung… Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView» weiterlesen - KI-Webseiten petzen und beeinflussen
 Klar kann man die KI manchmal zu verräterischem Verhalten verleiten. Aber noch einfacher ist es, wenn die Webseite ihre Anweisungen… KI-Webseiten petzen und beeinflussen weiterlesen
Klar kann man die KI manchmal zu verräterischem Verhalten verleiten. Aber noch einfacher ist es, wenn die Webseite ihre Anweisungen… KI-Webseiten petzen und beeinflussen weiterlesen
Lange Artikel (mehr…)
- Persönliche Daten für Facebook-KI
 Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle… Persönliche Daten für Facebook-KI weiterlesen
Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle… Persönliche Daten für Facebook-KI weiterlesen - KI-Datenkreisläufe
 Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude.
Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude. - Der Homo Ludens muss Werkzeuge spielend erfahren. Auch KI
 Fast alle Werkzeuge, die wir «spielend» beherrschen, haben wir spielend gelernt. Das sollten wir auch bei generativer KI.
Fast alle Werkzeuge, die wir «spielend» beherrschen, haben wir spielend gelernt. Das sollten wir auch bei generativer KI. - Der Turing-Test im Laufe der Zeit
 Vor einem knappen Jahrhundert hat sich Alan Turing mit den Fundamenten der heutigen Informatik beschäftigt: Kryptographie, Komplexität/Rechenaufwand, aber auch, ob und wie wir erkennen könnten, ob Computer „intelligent“ seien. Dieses… Der Turing-Test im Laufe der Zeit weiterlesen
Vor einem knappen Jahrhundert hat sich Alan Turing mit den Fundamenten der heutigen Informatik beschäftigt: Kryptographie, Komplexität/Rechenaufwand, aber auch, ob und wie wir erkennen könnten, ob Computer „intelligent“ seien. Dieses… Der Turing-Test im Laufe der Zeit weiterlesen - «QualityLand» sagt die Gegenwart voraus und erklärt sie
 Ich habe vor Kurzem das Buch «QualityLand» von Marc-Uwe Kling von 2017 in meinem Büchergestell gefunden. Und war erstaunt, wie akkurat es die Gegenwart erklärt. Eine Leseempfehlung.
Ich habe vor Kurzem das Buch «QualityLand» von Marc-Uwe Kling von 2017 in meinem Büchergestell gefunden. Und war erstaunt, wie akkurat es die Gegenwart erklärt. Eine Leseempfehlung. - Neuralink ist (noch) keine Schlagzeile wert
 Diese Woche haben einige kurze Tweets von Elon Musk hunderte oder gar tausende von Artikeln ausgelöst. Wieso?
Diese Woche haben einige kurze Tweets von Elon Musk hunderte oder gar tausende von Artikeln ausgelöst. Wieso? - «Quasselquote» bei LLM-Sprachmodellen
 Neulich erwähnte jemand, dass man ChatGPT-Output bei Schülern häufig an der «Quasselquote» erkennen könne. Das ist eine Nebenwirkung der Funktionsweise dieser Sprachmodelle, aber natürlich noch kein Beweis. Etwas Hintergrund.
Neulich erwähnte jemand, dass man ChatGPT-Output bei Schülern häufig an der «Quasselquote» erkennen könne. Das ist eine Nebenwirkung der Funktionsweise dieser Sprachmodelle, aber natürlich noch kein Beweis. Etwas Hintergrund. - «KI» und «Vertrauen»: Passt das zusammen?
 Vor einigen Wochen hat Bruce Schneier einen Vortrag gehalten, bei dem er vor der der Vermischung und Fehlinterpretation des Begriffs «Vertrauen» gewarnt hat, ganz besonders beim Umgang mit dem, was… «KI» und «Vertrauen»: Passt das zusammen? weiterlesen
Vor einigen Wochen hat Bruce Schneier einen Vortrag gehalten, bei dem er vor der der Vermischung und Fehlinterpretation des Begriffs «Vertrauen» gewarnt hat, ganz besonders beim Umgang mit dem, was… «KI» und «Vertrauen»: Passt das zusammen? weiterlesen - Wegweiser für generative KI-Tools
 Es gibt inzwischen eine grosse Anzahl generativer KI-Tools, nicht nur für den Unterricht. Hier ein Überblick über verschiedene Tool-Sammlungen.
Es gibt inzwischen eine grosse Anzahl generativer KI-Tools, nicht nur für den Unterricht. Hier ein Überblick über verschiedene Tool-Sammlungen. - KI-Vergiftung
 Eine aggressive Alternative zur Blockade von KI-Crawlern ist das «Vergiften» der dahinterliegenden KI-Modelle. Was bedeutet das?
Eine aggressive Alternative zur Blockade von KI-Crawlern ist das «Vergiften» der dahinterliegenden KI-Modelle. Was bedeutet das? - Lehrerverband, ChatGPT und Datenschutz
 Der Dachverband der Lehrerinnen und Lehrer (LCH) sei besorgt, dass es in der Schweiz keine einheitliche Regelung gäbe, wie Lehrpersonen mit Daten ihrer Schützlinge umgehen sollen und ob sie dafür… Lehrerverband, ChatGPT und Datenschutz weiterlesen
Der Dachverband der Lehrerinnen und Lehrer (LCH) sei besorgt, dass es in der Schweiz keine einheitliche Regelung gäbe, wie Lehrpersonen mit Daten ihrer Schützlinge umgehen sollen und ob sie dafür… Lehrerverband, ChatGPT und Datenschutz weiterlesen - Goethe oder GPThe?
 In «Wie funktioniert ChatGPT?» habe ich die Experimente von Andrej Karpathy mit Shakespeare-Texten wiedergegeben. Aber funktioniert das auch auf Deutsch? Zum Beispiel mit Goethe? Finden wir es heraus!
In «Wie funktioniert ChatGPT?» habe ich die Experimente von Andrej Karpathy mit Shakespeare-Texten wiedergegeben. Aber funktioniert das auch auf Deutsch? Zum Beispiel mit Goethe? Finden wir es heraus! - KI: Alles nur Zufall?
 Wer von einer «Künstlichen Intelligenz» Texte oder Bilder erzeugen lässt, weiss, dass das Resultat stark auf Zufall beruht. Vor Kurzem erschien in der NZZ ein Beitrag, der die Unzuverlässigkeit der… KI: Alles nur Zufall? weiterlesen
Wer von einer «Künstlichen Intelligenz» Texte oder Bilder erzeugen lässt, weiss, dass das Resultat stark auf Zufall beruht. Vor Kurzem erschien in der NZZ ein Beitrag, der die Unzuverlässigkeit der… KI: Alles nur Zufall? weiterlesen - Hype-Tech
 Wieso tauchen gewisse Hype-Themen wie Blockchain oder Maschinelles Lernen/Künstliche Intelligenz regelmässig in IT-Projekten auf, obwohl die Technik nicht wirklich zur gewünschten Lösung passt? Oder es auch einfachere, bessere Ansätze gäbe?
Wieso tauchen gewisse Hype-Themen wie Blockchain oder Maschinelles Lernen/Künstliche Intelligenz regelmässig in IT-Projekten auf, obwohl die Technik nicht wirklich zur gewünschten Lösung passt? Oder es auch einfachere, bessere Ansätze gäbe? - 📹 Die Technik hinter ChatGPT
 Der Digital Learning Hub organisierte 3 Impuls-Workshops zum Einsatz von ChatGPT in der Sekundarstufe II. Im dritten Teil präsentierte ich die Technik hinter ChatGPT. In der halben Stunde Vortrag werden… 📹 Die Technik hinter ChatGPT weiterlesen
Der Digital Learning Hub organisierte 3 Impuls-Workshops zum Einsatz von ChatGPT in der Sekundarstufe II. Im dritten Teil präsentierte ich die Technik hinter ChatGPT. In der halben Stunde Vortrag werden… 📹 Die Technik hinter ChatGPT weiterlesen - Ist ChatGPT für Ihre Anwendung ungefährlich?
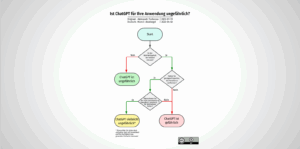 Ob man KI-Chatbots sicher einsetzen kann, hängt von der Anwendung ab. Aleksandr Tiulkanov hat deshalb ein Flussdiagramm als Entscheidungshilfe erstellt. Hier eine deutsche Übersetzung und ein paar Anmerkungen zum Korrekturlesen… Ist ChatGPT für Ihre Anwendung ungefährlich? weiterlesen
Ob man KI-Chatbots sicher einsetzen kann, hängt von der Anwendung ab. Aleksandr Tiulkanov hat deshalb ein Flussdiagramm als Entscheidungshilfe erstellt. Hier eine deutsche Übersetzung und ein paar Anmerkungen zum Korrekturlesen… Ist ChatGPT für Ihre Anwendung ungefährlich? weiterlesen - Wie funktioniert ChatGPT?
 ChatGPT ist wohl das zur Zeit mächtigste Künstliche-Intelligenz-Sprachmodell. Wir schauen etwas hinter die Kulissen, wie das „large language model“ GPT-3 und das darauf aufsetzende ChatGPT funktionieren.
ChatGPT ist wohl das zur Zeit mächtigste Künstliche-Intelligenz-Sprachmodell. Wir schauen etwas hinter die Kulissen, wie das „large language model“ GPT-3 und das darauf aufsetzende ChatGPT funktionieren. - Die KI ChatGPT und die Herausforderungen für die Gesellschaft
 Was lange währt, wird endlich, äh, published. Mein neuer DNIP-Artikel zu ChatGPT ist online, in drei Teilen:
Was lange währt, wird endlich, äh, published. Mein neuer DNIP-Artikel zu ChatGPT ist online, in drei Teilen: - Identifikation von KI-Kunst
 KI-Kunst ist auf dem Vormarsch, sowohl was die Qualität als auch die Quantität betrifft. Es liegt (leider) in der menschlichen Natur, einiges davon als „echte“, menschgeschaffene Kunst zu vermarkten. Hier… Identifikation von KI-Kunst weiterlesen
KI-Kunst ist auf dem Vormarsch, sowohl was die Qualität als auch die Quantität betrifft. Es liegt (leider) in der menschlichen Natur, einiges davon als „echte“, menschgeschaffene Kunst zu vermarkten. Hier… Identifikation von KI-Kunst weiterlesen - Die Lieblingsfragen von ChatGPT
 Entmutigt durch die vielen Antworten von ChatGPT, es könne mir auf diese oder jene Frage keine Antwort geben, weil es nur ein von OpenAI trainiertes Sprachmodell sei, versuchte ich, ChatGPT… Die Lieblingsfragen von ChatGPT weiterlesen
Entmutigt durch die vielen Antworten von ChatGPT, es könne mir auf diese oder jene Frage keine Antwort geben, weil es nur ein von OpenAI trainiertes Sprachmodell sei, versuchte ich, ChatGPT… Die Lieblingsfragen von ChatGPT weiterlesen - Wie funktioniert Künstliche Intelligenz?
 Am vergangenen Mittwoch habe ich im Rahmen der Volkshochschule Stein am Rhein einen Überblick über die Mächtigkeit, aber auch die teilweise Ohnmächtigkeit der Künstlichen Intelligenz gegeben. Das zahlreich anwesende Publikum… Wie funktioniert Künstliche Intelligenz? weiterlesen
Am vergangenen Mittwoch habe ich im Rahmen der Volkshochschule Stein am Rhein einen Überblick über die Mächtigkeit, aber auch die teilweise Ohnmächtigkeit der Künstlichen Intelligenz gegeben. Das zahlreich anwesende Publikum… Wie funktioniert Künstliche Intelligenz? weiterlesen - Künstliche Intelligenz — und jetzt?
 Am 16. November 2022 halte ich einen öffentlichen Vortrag zu künstlicher Intelligenz an der VHS Stein am Rhein. Sie sind herzlich eingeladen. Künstliche Intelligenz ist derzeit in aller Munde und… Künstliche Intelligenz — und jetzt? weiterlesen
Am 16. November 2022 halte ich einen öffentlichen Vortrag zu künstlicher Intelligenz an der VHS Stein am Rhein. Sie sind herzlich eingeladen. Künstliche Intelligenz ist derzeit in aller Munde und… Künstliche Intelligenz — und jetzt? weiterlesen - Reproduzierbare KI: Ein Selbstversuch
 Im NZZ Folio vom 6. September 2022 beschrieb Reto U. Schneider u.a., wie er mit DALL•E 2 Bilder erstellte. Die Bilder waren alle sehr eindrücklich. Ich fragte mich allerdings, wie viele… Reproduzierbare KI: Ein Selbstversuch weiterlesen
Im NZZ Folio vom 6. September 2022 beschrieb Reto U. Schneider u.a., wie er mit DALL•E 2 Bilder erstellte. Die Bilder waren alle sehr eindrücklich. Ich fragte mich allerdings, wie viele… Reproduzierbare KI: Ein Selbstversuch weiterlesen - Machine Learning: Künstliche Faultier-Intelligenz
 Machine Learning („ML“) wird als Wundermittel angepriesen um die Menschheit von fast allen repetitiven Verarbeitungsaufgaben zu entlasten: Von der automatischen Klassifizierung von Strassenschilden über medizinische Auswertungen von Gewebeproben bis zur… Machine Learning: Künstliche Faultier-Intelligenz weiterlesen
Machine Learning („ML“) wird als Wundermittel angepriesen um die Menschheit von fast allen repetitiven Verarbeitungsaufgaben zu entlasten: Von der automatischen Klassifizierung von Strassenschilden über medizinische Auswertungen von Gewebeproben bis zur… Machine Learning: Künstliche Faultier-Intelligenz weiterlesen





Schreibe einen Kommentar