
Neulich erwähnte jemand, dass man ChatGPT-Output bei Schülern häufig an der «Quasselquote» erkennen könne. Das ist eine Nebenwirkung der Funktionsweise dieser Sprachmodelle, aber natürlich noch kein Beweis. Etwas Hintergrund.
Sprachmodelle wie ChatGPT erzeugen ihren Output („Antworten“ etc.) Bruchstück für Bruchstück (genannt Token), typischerweise jeweils ein paar Buchstaben aufs Mal. Wer schon einmal mit einem dieser sogenannten LLMs (Large Language Model) gespielt hat, hat das sicher auch schon bemerkt.
Eine hohe Quasselquote wird beispielsweise hier sichtbar: Als Anfrager möchte ich nicht eine ganze Schulstunde für Drittklässler über Dreisatz aufgetischt bekommen, sondern einfach die Antwort wissen!
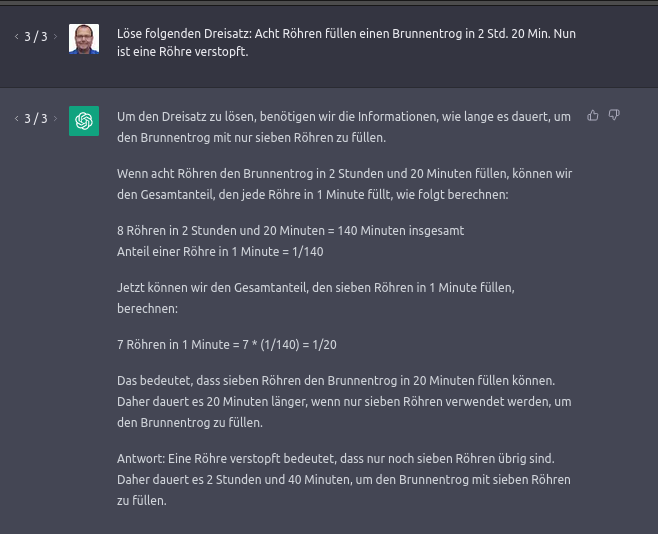
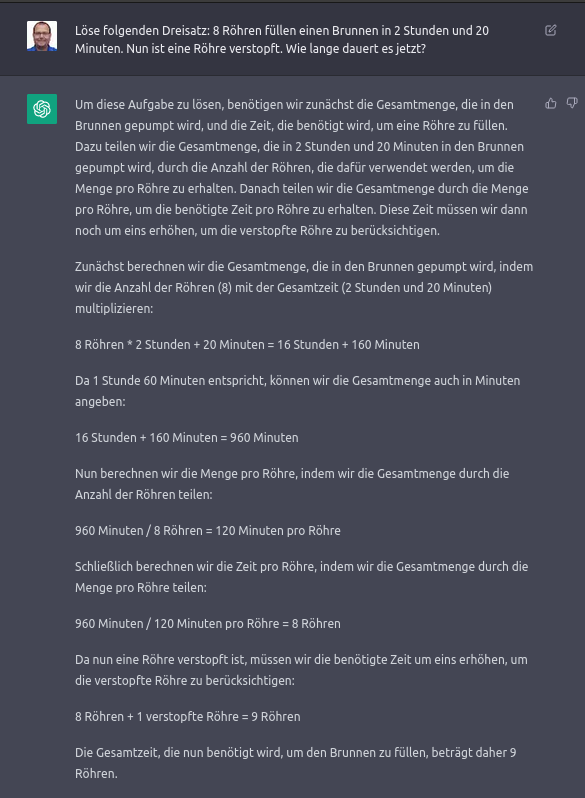
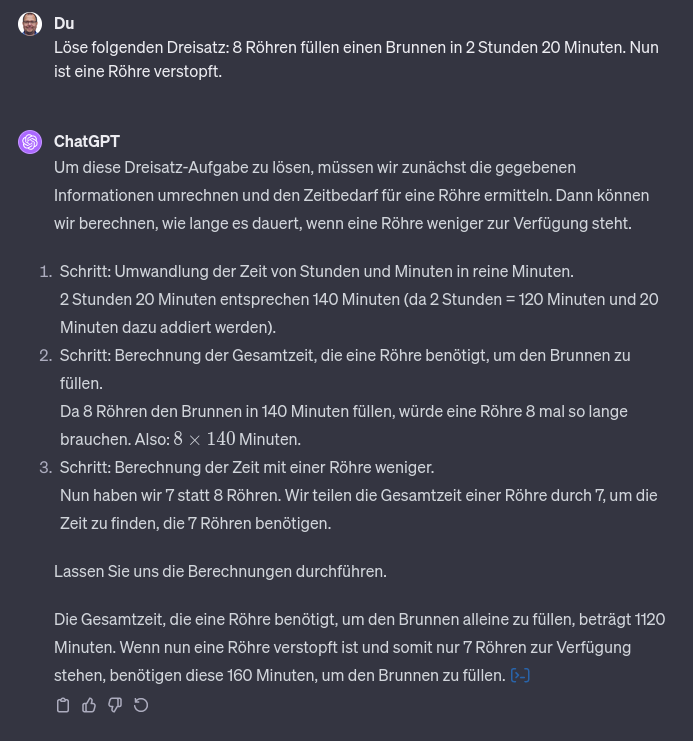
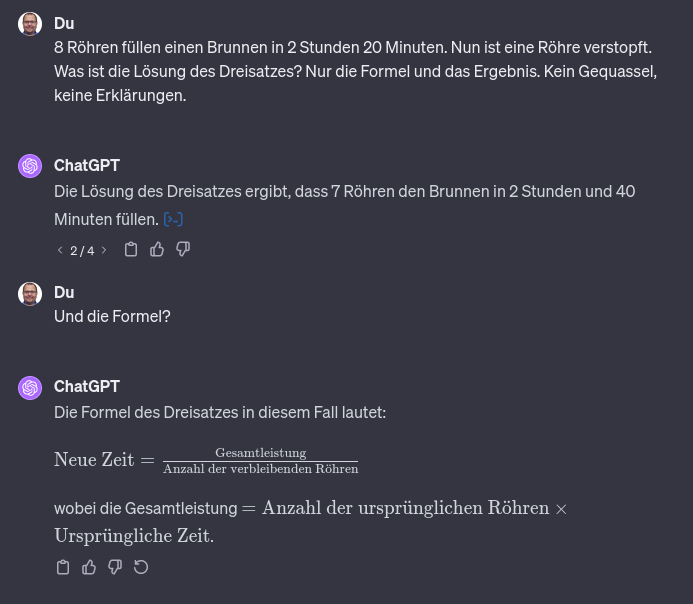
Der Grund hängt am fehlenden Verständnis für den Anfrager und an der Art, wie die Antwort generiert werden.
Grosse Sprachmodelle (LLM, Large Language Model) „denken“ auch immer nur ans nächste Token. Es existiert vorgängig kein Konzept, keine Skizze, was sie erzählen wollen. Das „Gehirn“ wird nicht vor dem Reden eingeschaltet, sondern es wird munter drauflos geredet, in der „Hoffnung“, dass dann schon etwas Brauchbares herauskomme.
Wir Menschen gehen davon aus, dass—wenn wir etwas erklären müssen—uns zumindest ganz grob überlegt haben, was wir eigentlich sagen wollen. Erst recht, wenn wir diese Erklärung aufschreiben wollen.
Wir haben einen Plan. Und wenn wir den nicht schon von Anfang an haben, dann legen wir ihn uns zwischendurch mal zurecht und beginnen vielleicht nochmals von vorne oder schreiben den Text um.
Die aktuellen Sprachmodelle haben diesen Luxus nicht. Nicht nur kennen sie das Konzept „Planung“ nicht, sie schreiben auch absolut linear. Ohne Ausnahme.
Entsprechend gibt es keine Plan, wie ein Dreisatz präsentiert werden soll. ChatGPT erzeugt einfach mal munter Text zum Thema „Dreisatz“ und dem konkreten Kontext passenden Text.
Klar, das jeweils nächste Token wird erzeugt, dass es irgendwie (meistens sogar recht gut) zum bisherigen Text (Frage+Antwort) passt, indem aus allen antrainierten Mustern eine Kombination ausgewählt wird.
Ex Post
Ob die Erklärung gut war, wird erst im Nachhinein evaluiert. Eines der möglichen erzeugten Token ist das spezielle „ENDE“-Token. Es ist unsichtbar, wechselt aber vom Ausgabe- in den „Warten auf die nächste Eingabe“-Modus.
Je besser die bisherigen Antwort einem der möglichen Muster für eine gute Antwort entspricht, desto wahrscheinlicher ist die Ausgabe dieses Tokens und damit das Ende der Erklärung.
Wenn der erste Erklärungsversuch nicht gut genug für das „ENDE“-Token war, wird einfach weitergeschrieben. Bis irgendwann die Erklärung als „gut genug“ eingestuft wird.
Und zu dem Zeitpunkt ist möglicherweise schon viel mittelmässiger oder gar schlechter Text entstanden. Da gibt es jetzt aber kein Zurück mehr.
Entsprechend kann ChatGPT-Text eine hohe Quasselquote aufweisen. Oder, wie ich es jeweils sage:
Es sieht so aus, als ob ein Prüfling bei einer Prüfung alles aufgeschrieben habe, was ihm in den Sinn gekommen sei. In der Hoffnung, dass der Lehrer bzw. die Lehrerin dann schon das daraus liest, was er/sie gerne sehen möchte.
Künstliche Intelligenz
News (mehr…)
- «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich
 Forschende der Uni Zürich haben KI-Bots in ein Forum der Plattform Reddit eingeschleust. Und zwar ohne Wissen der Betreiber:innen und User:innen. In diesem Forum, «ChangeMyView», fordern die Teilnehmenden dazu auf,… «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich weiterlesen
Forschende der Uni Zürich haben KI-Bots in ein Forum der Plattform Reddit eingeschleust. Und zwar ohne Wissen der Betreiber:innen und User:innen. In diesem Forum, «ChangeMyView», fordern die Teilnehmenden dazu auf,… «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich weiterlesen - Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView»
 Wie DNIP.ch am Montag als erstes Medium berichtete, hat eine Forschungsgruppe mit Anbindung zur Universität Zürich mittels KI psychologische Forschung an Menschen durchgeführt, ohne dass diese Menschen über die Studie… Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView» weiterlesen
Wie DNIP.ch am Montag als erstes Medium berichtete, hat eine Forschungsgruppe mit Anbindung zur Universität Zürich mittels KI psychologische Forschung an Menschen durchgeführt, ohne dass diese Menschen über die Studie… Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView» weiterlesen - KI-Webseiten petzen und beeinflussen
 Klar kann man die KI manchmal zu verräterischem Verhalten verleiten. Aber noch einfacher ist es, wenn die Webseite ihre Anweisungen an die KI selbst verrät.
Klar kann man die KI manchmal zu verräterischem Verhalten verleiten. Aber noch einfacher ist es, wenn die Webseite ihre Anweisungen an die KI selbst verrät.
Lange Artikel (mehr…)
- Persönliche Daten für Facebook-KI
 Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle… Persönliche Daten für Facebook-KI weiterlesen
Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle… Persönliche Daten für Facebook-KI weiterlesen - KI-Datenkreisläufe
 Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude.
Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude. - Der Homo Ludens muss Werkzeuge spielend erfahren. Auch KI
 Fast alle Werkzeuge, die wir «spielend» beherrschen, haben wir spielend gelernt. Das sollten wir auch bei generativer KI.
Fast alle Werkzeuge, die wir «spielend» beherrschen, haben wir spielend gelernt. Das sollten wir auch bei generativer KI. - Der Turing-Test im Laufe der Zeit
 Vor einem knappen Jahrhundert hat sich Alan Turing mit den Fundamenten der heutigen Informatik beschäftigt: Kryptographie, Komplexität/Rechenaufwand, aber auch, ob und wie wir erkennen könnten, ob Computer „intelligent“ seien. Dieses… Der Turing-Test im Laufe der Zeit weiterlesen
Vor einem knappen Jahrhundert hat sich Alan Turing mit den Fundamenten der heutigen Informatik beschäftigt: Kryptographie, Komplexität/Rechenaufwand, aber auch, ob und wie wir erkennen könnten, ob Computer „intelligent“ seien. Dieses… Der Turing-Test im Laufe der Zeit weiterlesen - «QualityLand» sagt die Gegenwart voraus und erklärt sie
 Ich habe vor Kurzem das Buch «QualityLand» von Marc-Uwe Kling von 2017 in meinem Büchergestell gefunden. Und war erstaunt, wie akkurat es die Gegenwart erklärt. Eine Leseempfehlung.
Ich habe vor Kurzem das Buch «QualityLand» von Marc-Uwe Kling von 2017 in meinem Büchergestell gefunden. Und war erstaunt, wie akkurat es die Gegenwart erklärt. Eine Leseempfehlung. - Neuralink ist (noch) keine Schlagzeile wert
 Diese Woche haben einige kurze Tweets von Elon Musk hunderte oder gar tausende von Artikeln ausgelöst. Wieso?
Diese Woche haben einige kurze Tweets von Elon Musk hunderte oder gar tausende von Artikeln ausgelöst. Wieso? - «Quasselquote» bei LLM-Sprachmodellen
 Neulich erwähnte jemand, dass man ChatGPT-Output bei Schülern häufig an der «Quasselquote» erkennen könne. Das ist eine Nebenwirkung der Funktionsweise dieser Sprachmodelle, aber natürlich noch kein Beweis. Etwas Hintergrund. Sprachmodelle… «Quasselquote» bei LLM-Sprachmodellen weiterlesen
Neulich erwähnte jemand, dass man ChatGPT-Output bei Schülern häufig an der «Quasselquote» erkennen könne. Das ist eine Nebenwirkung der Funktionsweise dieser Sprachmodelle, aber natürlich noch kein Beweis. Etwas Hintergrund. Sprachmodelle… «Quasselquote» bei LLM-Sprachmodellen weiterlesen - «KI» und «Vertrauen»: Passt das zusammen?
 Vor einigen Wochen hat Bruce Schneier einen Vortrag gehalten, bei dem er vor der der Vermischung und Fehlinterpretation des Begriffs «Vertrauen» gewarnt hat, ganz besonders beim Umgang mit dem, was… «KI» und «Vertrauen»: Passt das zusammen? weiterlesen
Vor einigen Wochen hat Bruce Schneier einen Vortrag gehalten, bei dem er vor der der Vermischung und Fehlinterpretation des Begriffs «Vertrauen» gewarnt hat, ganz besonders beim Umgang mit dem, was… «KI» und «Vertrauen»: Passt das zusammen? weiterlesen - Wegweiser für generative KI-Tools
 Es gibt inzwischen eine grosse Anzahl generativer KI-Tools, nicht nur für den Unterricht. Hier ein Überblick über verschiedene Tool-Sammlungen.
Es gibt inzwischen eine grosse Anzahl generativer KI-Tools, nicht nur für den Unterricht. Hier ein Überblick über verschiedene Tool-Sammlungen. - KI-Vergiftung
 Eine aggressive Alternative zur Blockade von KI-Crawlern ist das «Vergiften» der dahinterliegenden KI-Modelle. Was bedeutet das?
Eine aggressive Alternative zur Blockade von KI-Crawlern ist das «Vergiften» der dahinterliegenden KI-Modelle. Was bedeutet das? - Lehrerverband, ChatGPT und Datenschutz
 Der Dachverband der Lehrerinnen und Lehrer (LCH) sei besorgt, dass es in der Schweiz keine einheitliche Regelung gäbe, wie Lehrpersonen mit Daten ihrer Schützlinge umgehen sollen und ob sie dafür… Lehrerverband, ChatGPT und Datenschutz weiterlesen
Der Dachverband der Lehrerinnen und Lehrer (LCH) sei besorgt, dass es in der Schweiz keine einheitliche Regelung gäbe, wie Lehrpersonen mit Daten ihrer Schützlinge umgehen sollen und ob sie dafür… Lehrerverband, ChatGPT und Datenschutz weiterlesen - Goethe oder GPThe?
 In «Wie funktioniert ChatGPT?» habe ich die Experimente von Andrej Karpathy mit Shakespeare-Texten wiedergegeben. Aber funktioniert das auch auf Deutsch? Zum Beispiel mit Goethe? Finden wir es heraus!
In «Wie funktioniert ChatGPT?» habe ich die Experimente von Andrej Karpathy mit Shakespeare-Texten wiedergegeben. Aber funktioniert das auch auf Deutsch? Zum Beispiel mit Goethe? Finden wir es heraus! - KI: Alles nur Zufall?
 Wer von einer «Künstlichen Intelligenz» Texte oder Bilder erzeugen lässt, weiss, dass das Resultat stark auf Zufall beruht. Vor Kurzem erschien in der NZZ ein Beitrag, der die Unzuverlässigkeit der… KI: Alles nur Zufall? weiterlesen
Wer von einer «Künstlichen Intelligenz» Texte oder Bilder erzeugen lässt, weiss, dass das Resultat stark auf Zufall beruht. Vor Kurzem erschien in der NZZ ein Beitrag, der die Unzuverlässigkeit der… KI: Alles nur Zufall? weiterlesen - Hype-Tech
 Wieso tauchen gewisse Hype-Themen wie Blockchain oder Maschinelles Lernen/Künstliche Intelligenz regelmässig in IT-Projekten auf, obwohl die Technik nicht wirklich zur gewünschten Lösung passt? Oder es auch einfachere, bessere Ansätze gäbe?
Wieso tauchen gewisse Hype-Themen wie Blockchain oder Maschinelles Lernen/Künstliche Intelligenz regelmässig in IT-Projekten auf, obwohl die Technik nicht wirklich zur gewünschten Lösung passt? Oder es auch einfachere, bessere Ansätze gäbe? - 📹 Die Technik hinter ChatGPT
 Der Digital Learning Hub organisierte 3 Impuls-Workshops zum Einsatz von ChatGPT in der Sekundarstufe II. Im dritten Teil präsentierte ich die Technik hinter ChatGPT. In der halben Stunde Vortrag werden… 📹 Die Technik hinter ChatGPT weiterlesen
Der Digital Learning Hub organisierte 3 Impuls-Workshops zum Einsatz von ChatGPT in der Sekundarstufe II. Im dritten Teil präsentierte ich die Technik hinter ChatGPT. In der halben Stunde Vortrag werden… 📹 Die Technik hinter ChatGPT weiterlesen





Schreibe einen Kommentar