
In «Wie funktioniert ChatGPT?» habe ich die Experimente von Andrej Karpathy mit Shakespeare-Texten wiedergegeben. Aber funktioniert das auch auf Deutsch? Zum Beispiel mit Goethe? Finden wir es heraus!
Die Quelle
Auf Project Gutenberg gibt es zur Zeit 40 Texte von Goethe in Deutsch. Von der Textstruktur könnte man sie beispielsweise in Gedichte, Theaterstücke und Fliesstext (Novellen, Tagebücher, Briefe, …) klassieren. Da wahrscheinlich bei den meisten auf das Stichwort «Goethe» zuerst die Assoziation «Faust» einfallen dürfte, habe ich mir die 13 Theaterstücke ausgesucht und den englischen (und nicht von Goethe stammenden) Gutenberg-Vor- und z.T. -Abspann entfernt (von Hand, da sie in fast jeder Datei anders sind). Die Werke sind (in der Reihenfolge ihres Eingangs auf gutenberg.org):
- Iphigenie auf Tauris
- Egmont
- Faust: Der Tragödie erster Teil
- Faust: Der Tragödie zweiter Teil
- Götz von Berlichingen mit der eisernen Hand: Ein Schauspiel
- Die Geschwister: Ein Schauspiel in einem Akt
- Die Mitschuldigen
- Prometheus
- Satyros oder Der vergötterte Waldteufel
- Die Laune des Verliebten
- Torquato Tasso
- Die natürliche Tochter
- Die Aufgeregten
Auch dann noch sind sie unterschiedlich formatiert:
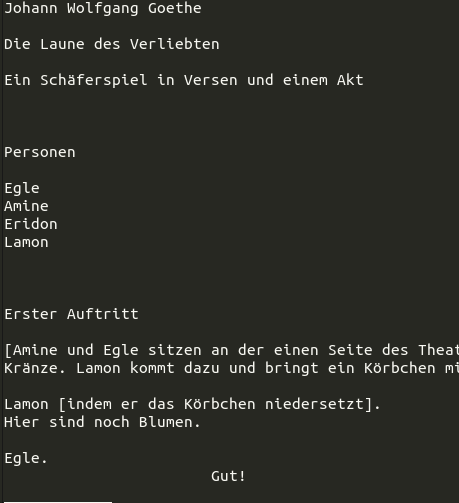
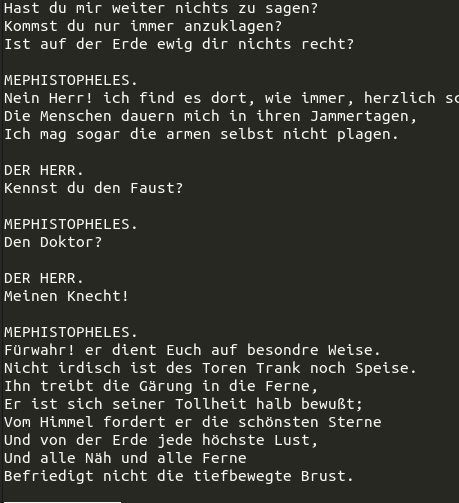

Eine Vereinheitlichung der Struktur vorab hätte sich wohl positiv auf die Ergebnisse ausgewirkt; für dieses erste Experiment wollte ich den Aufwand aber nicht treiben.
Die Trainingsdaten
Karpathy fügt die Werke Shakespeares aneinander und verwendet die ersten 90% des resultierenden Textes als Trainingsdaten für das Modell, die letzten 10% zu seiner Validierung. (Scheinbar sind in den Shakespeare-Texten nur die Dialoge vorhanden, keine Handlungsanweisungen o.ä.)
Mit der Validierung (manchmal auch «Test») wird überprüft, wie ähnlich die aus dem Modell generierten Texte anderen Goethe-Texten sind, die das Modell garantiert noch nicht gesehen hat. Damit soll u.a. erreicht werden, dass das Modell nicht nur Goethe-Texte 1:1 wiedergeben kann, sondern Goethe-ähnliche Texte erzeugen kann. «Goethe-gleiche» Texte sind nicht gewünscht, denn sie liessen sich auch einfacher, z.B. mittels Copy+Paste, erzeugen.
Beim Zusammenfügen der Dateien in der alphabetischen Reihenfolge ihres Namens wären «Die Geschwister», «Die Mitschuldigen» und «Prometheus» (und der Schluss vom «Götz von Berlichingen») zu den Validierungsdaten geworden. Dies erschien mir wenig repräsentativ, weshalb ich eine andere Aufteilung als Karpathy wählte:
- Die ersten und letzten 45% jeden Stücks wurden zu Trainingsdaten.
- Die mittleren 10% (von 45 bis 55%) wurden zu Test- bzw. Validierungsdaten.
Von den insgesamt ca. 1.5 Megabyte Text waren damit 1.35 MB Trainingsdaten (581’749 GPT-2-Token) und 150 kB Validierungsdaten (70’154 GPT-2-Token).
Das Probetraining
Da mir für dieses Experiment keine leistungsfähige Grafikkarte zur Verfügung stand, nutzte ich für einen ersten Versuch die von Karpathy empfohlenen Einstellungen für Leute, die «nur einen billigen Computer» haben.
Nach wenigen Minuten war das Training beendet, bei einem «validation loss» (Qualitätsmass für die Ähnlichkeit der erzeugten Texte zu den Validierungsdaten; niedriger ist besser) von 3.4719. Karpathy erzielt mit Shakespeare und Grafikkarte (d.h. den Einstellungen für Leute, die einen richtigen Computer haben, und damit einem deutlich grösseren und komplexeren Modell) einen validation loss von 1.4967.
Ich rechnete also mit Texten, welche nicht viel mit Goethe gemeinsam hätten. Und wurde nicht enttäuscht:
Von dieses Glückt ihm ich mich zu würde,
Sind es soll’s in solchen Sorge dich verpfärtner wir lang.Psyche.
Verlang mir verließt’s! Du nein Wieht,
Ich wärste zu einem jungen,
Dich wärehren sie nicht viel gehe.MARGARETE.
Wenn wir hinabte,
Ich seinen Pfalt!Ich kann sollt, oder Ihr seh,
nanoGPT versucht sich an Goethe (mit den Einstellungen für «Billigcomputer»)
Rug viel; was man mir gek;
So verschwind, so hab ich nichts zu hin,
Die gar zu wohl,
Doch lährt’ ich nicht überfreu.
Du mich, weißt er,
Da wärst du meinem Heiligen wahre
Dein angesten, ein jeder Götterndet.
Der Text beinhaltet relativ viele deutsche Wörter. Es klang vielversprechend, jetzt sollte ein richtiges Training her!
Die Hauptprobe
Ich spielte etwas mit den Modellparametern, bis ich eine Kombination hatte, die meinen Rechner über Nacht auslasten würde: Bis auf die Blockgrösse (und versehentlich eval_iters=50) waren schlussendlich alle Parameter gleich mit denen, die ein «richtiger Rechner» innert weniger Minuten trainieren könnte (bei mir sollte es, wie gesagt, die ganzen Nacht dauern). Die Blockgrösse sagt aus, wie weit entfernte Textzusammenhänge der «Attention»-Mechanismus von nanoGPT berücksichtigen kann, mehr ist besser. Der Standardwert liegt bei 256, ich wählte die Hälfte (128). Da ich den Text aber in Token (durchschnittlich ca. 2-3 Zeichen) verarbeitete und nicht in Zeichen, sollte dadurch kaum ein Nachteil entstehen.
Am nächsten Morgen sah ich erfreut Loss-Zahlen von 1.2 und 0.7 auf dem Bildschirm. Hurrah! Doch leider war der «eval loss» weiterhin bei 3.6616, also eigentlich sogar noch etwas schlechter als nach wenigen Minuten mit dem kleineren Modell.
Trotzdem, Wörter und Satzstrukturen wirken viel überzeugender:
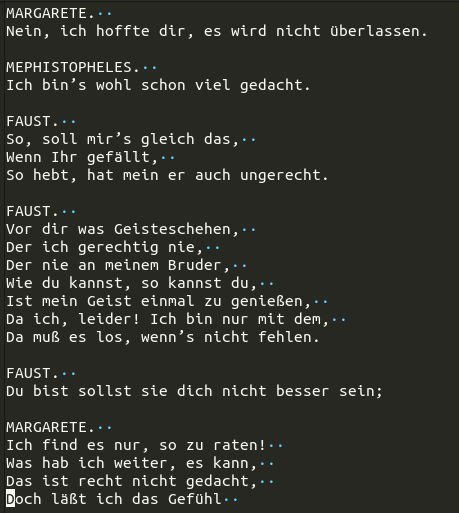
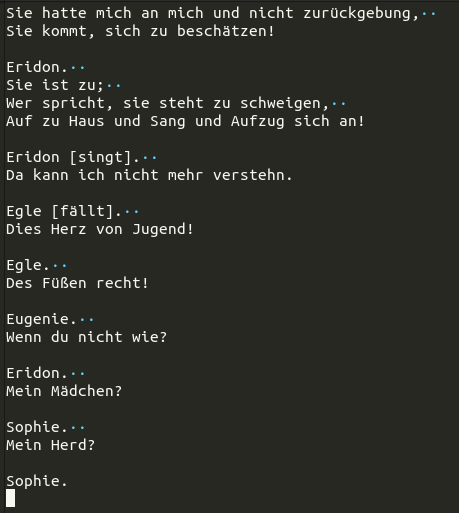

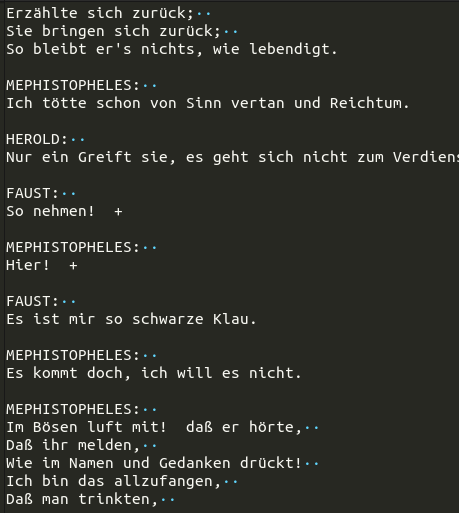



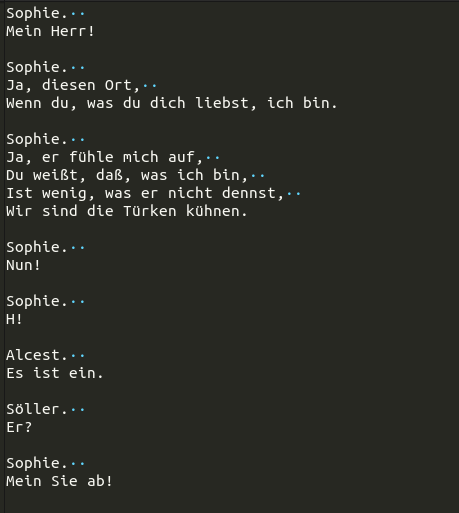

Für bessere Resultate bräuchte es wahrscheinlich mehr (und vereinheitlichte) Trainingsdaten und ein grösseres Modell. Es ist eben noch kein Meister vom Himmel gefallen. (Und auch nicht aus den Rechnern der Cloud.)
Was lernen wir daraus?
GPT kann Goethe (noch?) nicht ersetzen. Aber wir sehen, dass man auf seinem «Billigrechner» zuhause mit relativ einfacher Software wie nanoGPT (2 Mal 300 Zeilen Python, Zeile für Zeile erklärt in einem Zwei-Stunden-Video) schon Texte produzieren lassen kann, die vor wenigen Jahren noch weltbewegend gewesen wären.
Gleichzeitig wachsen neue Modelle fast wie Pilze aus dem Boden. Einige vielversprechende Modelle sind auch Open Source, das heisst, ganz viele begeisterte und talentierte Leute können ihre Ideen daran ausprobieren. Damit werden uns die Sprachmodelle sicher noch einige Zeit begleiten und ihre Eigenschaften sich verbessern.
Daten
- nanoGPT: Der Code (und Anleitung)
- Project Gutenberg: Goethe-Texte
- Meine gesäuberten Texte und Skripte (600 kB ZIP): Downloadskript für die Texte von Project Gutenberg; die ausgewählten Texte nach Entfernung des Vor- und Abspanns; Extraktionsskript für die 45-10-45-Separation
- Das Modell nach dem Durchrechnen durch die Nacht (300 MB ZIP)
- Generierter Output (8 kB ZIP): Jeweils vom «Billigcomputer»- und dem «Ganze Nacht durchgerechnet»-Modell
Künstliche Intelligenz
- Persönliche Daten für Facebook-KI
 Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle Beiträge (auch die zutiefst persönlichen), Bilder (auch die peinlichen) und Kommentare (auch die blöden Sprüche) auf Facebook und Instagram, die Interaktionen mit dem KI-Chatbot «Meta… Persönliche Daten für Facebook-KI weiterlesen
Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle Beiträge (auch die zutiefst persönlichen), Bilder (auch die peinlichen) und Kommentare (auch die blöden Sprüche) auf Facebook und Instagram, die Interaktionen mit dem KI-Chatbot «Meta… Persönliche Daten für Facebook-KI weiterlesen - «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich
 Forschende der Uni Zürich haben KI-Bots in ein Forum der Plattform Reddit eingeschleust. Und zwar ohne Wissen der Betreiber:innen und User:innen. In diesem Forum, «ChangeMyView», fordern die Teilnehmenden dazu auf, ihre Meinungen zu widerlegen. Nun haben zahlreiche von ihnen nichts ahnend mit Maschinen diskutiert und mitgelitten – eine KI gab sich etwa als Missbrauchsopfer aus.
Forschende der Uni Zürich haben KI-Bots in ein Forum der Plattform Reddit eingeschleust. Und zwar ohne Wissen der Betreiber:innen und User:innen. In diesem Forum, «ChangeMyView», fordern die Teilnehmenden dazu auf, ihre Meinungen zu widerlegen. Nun haben zahlreiche von ihnen nichts ahnend mit Maschinen diskutiert und mitgelitten – eine KI gab sich etwa als Missbrauchsopfer aus. - Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView»
 Wie DNIP.ch am Montag als erstes Medium berichtete, hat eine Forschungsgruppe mit Anbindung zur Universität Zürich mittels KI psychologische Forschung an Menschen durchgeführt, ohne dass diese Menschen über die Studie informiert waren. Aus guten Gründen (Vertrauen, Ethik, …) ist das in den meisten Fällen ein No-Go.
Wie DNIP.ch am Montag als erstes Medium berichtete, hat eine Forschungsgruppe mit Anbindung zur Universität Zürich mittels KI psychologische Forschung an Menschen durchgeführt, ohne dass diese Menschen über die Studie informiert waren. Aus guten Gründen (Vertrauen, Ethik, …) ist das in den meisten Fällen ein No-Go. - KI-Webseiten petzen und beeinflussen
 Klar kann man die KI manchmal zu verräterischem Verhalten verleiten. Aber noch einfacher ist es, wenn die Webseite ihre Anweisungen an die KI selbst verrät.
Klar kann man die KI manchmal zu verräterischem Verhalten verleiten. Aber noch einfacher ist es, wenn die Webseite ihre Anweisungen an die KI selbst verrät. - Können KI-Systeme Artikel klauen?
 Vor ein paar Wochen hat die NZZ einen Artikel veröffentlicht, in dem Petra Gössi das NZZ-Team erschreckte, weil via KI-Chatbot angeblich «beinahe der gesamte Inhalt des Artikels […] in der Antwort von Perplexity zu lesen» gewesen sei. Und nun könne «man gratis oder für eine Gebühr von etwa 20 Dollar pro Monat jede Zeitung auf… Können KI-Systeme Artikel klauen? weiterlesen
Vor ein paar Wochen hat die NZZ einen Artikel veröffentlicht, in dem Petra Gössi das NZZ-Team erschreckte, weil via KI-Chatbot angeblich «beinahe der gesamte Inhalt des Artikels […] in der Antwort von Perplexity zu lesen» gewesen sei. Und nun könne «man gratis oder für eine Gebühr von etwa 20 Dollar pro Monat jede Zeitung auf… Können KI-Systeme Artikel klauen? weiterlesen - Was verraten KI-Chatbots?
 «Täderlät» die KI? Vor ein paar Wochen fragte mich jemand besorgt, ob man denn gar nichts in Chatbot-Fenster eingeben könne, was man nicht auch öffentlich teilen würde. Während der Erklärung fiel mir auf, dass ganz viele Leute ganz wenig Ahnung haben, wie die Datenflüsse bei KI-Chatbots wie ChatGPT etc. eigentlich ablaufen. Deshalb habe ich für… Was verraten KI-Chatbots? weiterlesen
«Täderlät» die KI? Vor ein paar Wochen fragte mich jemand besorgt, ob man denn gar nichts in Chatbot-Fenster eingeben könne, was man nicht auch öffentlich teilen würde. Während der Erklärung fiel mir auf, dass ganz viele Leute ganz wenig Ahnung haben, wie die Datenflüsse bei KI-Chatbots wie ChatGPT etc. eigentlich ablaufen. Deshalb habe ich für… Was verraten KI-Chatbots? weiterlesen - KI-Datenkreisläufe
 Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude.
Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude. - Der Homo Ludens muss Werkzeuge spielend erfahren. Auch KI
 Fast alle Werkzeuge, die wir «spielend» beherrschen, haben wir spielend gelernt. Das sollten wir auch bei generativer KI.
Fast alle Werkzeuge, die wir «spielend» beherrschen, haben wir spielend gelernt. Das sollten wir auch bei generativer KI. - Der Turing-Test im Laufe der Zeit
 Vor einem knappen Jahrhundert hat sich Alan Turing mit den Fundamenten der heutigen Informatik beschäftigt: Kryptographie, Komplexität/Rechenaufwand, aber auch, ob und wie wir erkennen könnten, ob Computer „intelligent“ seien. Dieses Imitationsspiel kennen wir heute als Turing-Test und ist aktuell wieder in aller Munde, weil gerade behauptet wird, dass Computer inzwischen intelligenter seien als Menschen. Er… Der Turing-Test im Laufe der Zeit weiterlesen
Vor einem knappen Jahrhundert hat sich Alan Turing mit den Fundamenten der heutigen Informatik beschäftigt: Kryptographie, Komplexität/Rechenaufwand, aber auch, ob und wie wir erkennen könnten, ob Computer „intelligent“ seien. Dieses Imitationsspiel kennen wir heute als Turing-Test und ist aktuell wieder in aller Munde, weil gerade behauptet wird, dass Computer inzwischen intelligenter seien als Menschen. Er… Der Turing-Test im Laufe der Zeit weiterlesen - «QualityLand» sagt die Gegenwart voraus und erklärt sie
 Ich habe vor Kurzem das Buch «QualityLand» von Marc-Uwe Kling von 2017 in meinem Büchergestell gefunden. Und war erstaunt, wie akkurat es die Gegenwart erklärt. Eine Leseempfehlung.
Ich habe vor Kurzem das Buch «QualityLand» von Marc-Uwe Kling von 2017 in meinem Büchergestell gefunden. Und war erstaunt, wie akkurat es die Gegenwart erklärt. Eine Leseempfehlung. - Kritik an KI ist nötig. Aber wie?
 KI ist seit 1½ Jahren in aller Munde. Die Meinungen gehen von Woher kommt diese Uneinigkeit? Daran, dass die Kritik an der KI faul geworden sei und nur noch wiederkäue, meint Danilo Campos in einem Essay, das er Ende letzten Jahres geschrieben hat. Darin versucht er die Kritik an der KI zu strukturieren und zu… Kritik an KI ist nötig. Aber wie? weiterlesen
KI ist seit 1½ Jahren in aller Munde. Die Meinungen gehen von Woher kommt diese Uneinigkeit? Daran, dass die Kritik an der KI faul geworden sei und nur noch wiederkäue, meint Danilo Campos in einem Essay, das er Ende letzten Jahres geschrieben hat. Darin versucht er die Kritik an der KI zu strukturieren und zu… Kritik an KI ist nötig. Aber wie? weiterlesen - Neuralink ist (noch) keine Schlagzeile wert
 Diese Woche haben einige kurze Tweets von Elon Musk hunderte oder gar tausende von Artikeln ausgelöst. Wieso?
Diese Woche haben einige kurze Tweets von Elon Musk hunderte oder gar tausende von Artikeln ausgelöst. Wieso?





Schreibe einen Kommentar