Die durch Meltdown und Spectre ausgenutzten Sicherheitslücken sind zur Zeit in aller Munde. Und werden uns noch lange beschäftigen. Denn die Schwachstellen sind tief in den heutigen superschnellen Prozessoren verwurzelt. Sie erlauben es einer Schadsoftware, Daten zu lesen, ohne dass ein Befehl zum Lesen dieser Daten ausgeführt werden muss, mit der Folge, dass die üblichen Überprüfungen, ob dieser Lesebefehl auch berechtigt ist, ins Nichts laufen: ein riesiges Sicherheitsproblem! Deshalb sollten nicht nur eingefleischte InformatikerInnen die Hintergründe verstehen. Mein Versuch einer Erklärung für alle beginnt mit einem Schachspiel zwischen blutigen Anfängern; und endet mit einem Ausblick, was auf die IT-Industrie und uns alle zukommt.
1. Hintergrund und Überblick
Schach…
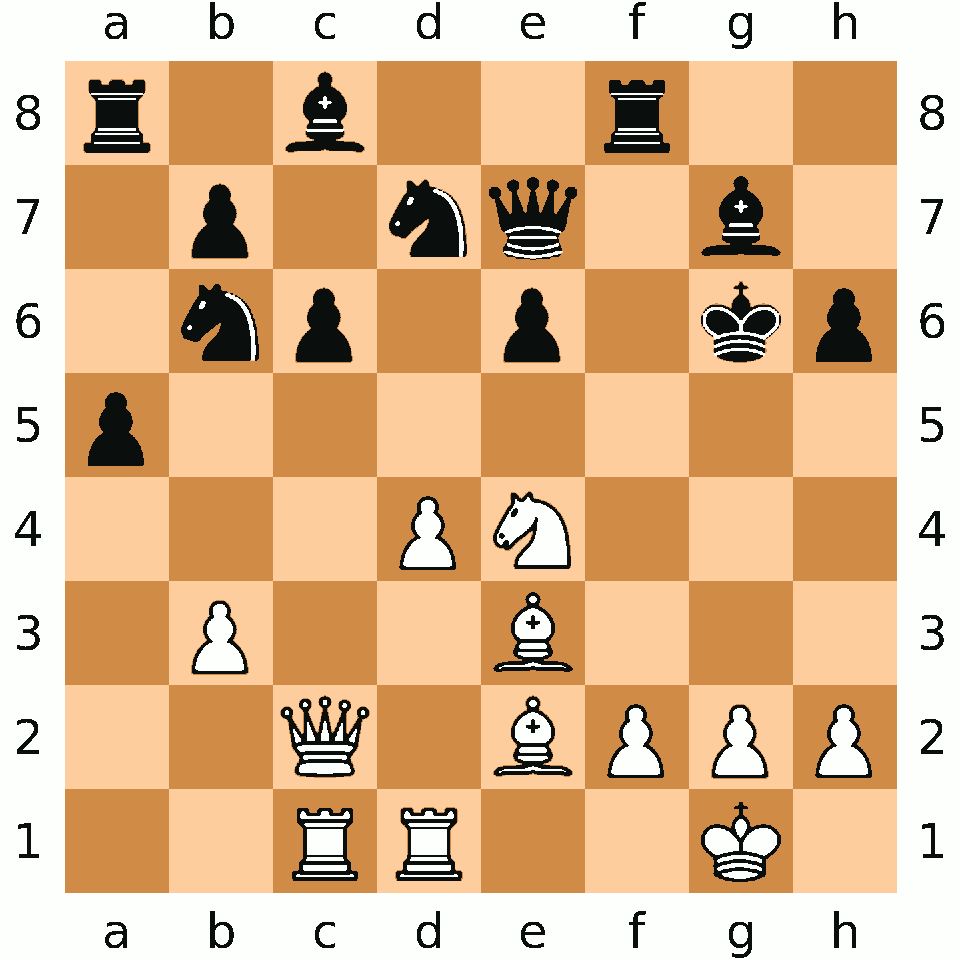
Zwei Anfänger, Melt Down und Pro Zessor, spielen gegeneinander Schach. Pro Zessor weiss nicht weiter. Melt Down, verzweifelt über das lange Warten, verabschiedet sich für 10 Minuten, um gegenüber einen Döner essen zu gehen. Pro Zessor beginnt, da sein Vorstellungsvermögen nicht so toll ist, auf dem Schachbrett mögliche nächste Züge auszuprobieren. Rechtzeitig vor der Rückkehr seines Gegners stellt er aber alle Figuren wieder an den ursprünglichen Platz und wähnt sich sicher.
Melt Down ist aber ausgefuchster, als er aussieht. Nach seiner Rückkehr schaut er flach über das Schachbrett und sieht, auf welchen Feldern weniger Staub liegt und kann damit die Strategie des armen Pro Zessor einmal mehr durchkreuzen.[1]Alternativ könnte er auch mit einer Wärmebildkamera die zuletzt angefassten Figuren identifizieren oder, oder, oder…
…und Prozessoren
So ähnlich funktionieren auch die Meltdown- und Spectre-Angriffe gegen Prozessoren: Der Prozessor schaut immer etwas voraus, damit er so schnell ist, wie wir ihn uns wünschen. Ohne diese Verbesserung hätten unsere Rechner nur einen Bruchteil ihrer heutigen Leistung. Allerdings hinterlässt dieses Vorausschauen (die Informatiker nennen das „spekulative Ausführung“ bzw. ennet dem Teich „speculative execution“) Spuren, ähnlich unauffällig und kurzfristig wie Staub. Aber wenn ein Gegner weiss, worauf er schauen muss, kann er auch schwächste Spuren deuten. Darüber hinaus ist es recht einfach möglich, den Prozessor dazu zu bringen, auf einem möglichst staubigen Schachbrett zu spielen und so noch mehr Spuren zu hinterlassen.
Aber wieso sind Prozessoren so naiv? Zuerst einmal sind sie darauf trainiert, alles zu machen, was ihnen der Programmierer befiehlt, solange es nicht explizit verboten ist. Auf der anderen Seite sind Prozessoren aber heute nur so leistungsfähig, weil sie hinter dem Rücken des Programmierers zu tricksen, was das Zeug hält, in der Hoffnung, dass es nicht auffällt. Wieso diese ganze Trickserei nötig ist und wie wir in dieses Schlamassel hinein gerutscht sind, erläutern die folgenden Abschnitte.
Auto=Prozessor?
Zuerst einmal: Prozessoren stehen da nicht ganz alleine da. In vielen anderen technischen Geräten lief eine ähnliche Entwicklung ab: Über Jahrzehnte hinweg konnten sie schneller und kräftiger gemacht werden. Irgendwann ging aber nur noch kleiner, was aber häufig nicht mehr alle Bedürfnisse abdeckt. So auch bei den Autos: Da konnte vor Jahrzehnten noch viel aus dem Motor herausgekitzelt werden und Höchstgeschwindigkeit war ein wichtiges Unterscheidungsmerkmal. Heute ist aus Sicht des Käufers am Motor kaum mehr etwas zu verbessern, also mussten andere Argumente her, wie z.B. schnellere Reaktionen oder kürzere Bremswege und die ganzen Assistenten, die es weiterhin erlauben, Zeit zu sparen, aber nicht mehr durch reale Erhöhung der Geschwindigkeit.
Vielleicht sind sich Autos und Prozessoren sogar noch ähnlicher, als wir denken. Wer weiss, die Prozessor-Sicherheitslücken und der Dieselskandal sind möglicherweise einfach der Ausdruck desselben jahrzehntelangen Erfolgsdrucks, der dann eben manchmal in die falsche Richtung zieht.
Abkürzungen…
Zurück zu den Prozessoren. Die ersten programmierbaren Computer entstanden in den 1940er-Jahren und bestanden aus tausenden von Relais. Das Schalten ging langsam (Hundertstelsekunden), die Leitungen waren (nicht nur sprichwörtlich) lang. Mit der Zeit wurden die Schaltvorgänge durch Röhren und Transistoren immer schneller und die Übertragungswege durch kleinere Bauteile, weniger Abwärme und später integrierte Schaltungen immer kürzer.
Der Prozessor konnte so Anfang der 90er abermillionen Male in der Sekunde einen Befehl aus dem Speicher laden und ihn ausführen. Und den nächsten Befehl laden und ihn ausführen. Und den nächsten. Und noch einen. Und so weiter.
Doch wirklich schneller wurden die Schaltgeschwindigkeiten nachher nicht mehr. Und es kam dazu, dass der Hauptspeicher, das RAM, das ausserhalb des Prozessors liegt, zwar immer noch grösser, aber kaum mehr schneller wurde.
…und Tricks
Den Bedarf an schnelleren Prozessoren konnte man also kaum mehr einfach durch Verkleinerung der Komponenten erfüllen.[2]Es gab einen Trend zu Prozessoren mit einfacheren Befehlen, die dann entsprechend schneller ausgeführt werden können (RISC-Prozessoren, insbesondere die in Mobilgeräten beliebten ARM-Prozessoren). Aber die klassischen CISC-Prozessoren mit ihrer grösseren Verbreitung und Marktmacht haben da einfach aufgeholt, indem sie intern wie RISC zu arbeiten begannen. Also mussten Tricks her, damit es weiterhin so aussah, als ob schön brav ein Befehl nach dem anderen ausgeführt werde, aber intern mehrere Befehle gleichzeitig abgearbeitet werden konnten. Das machte den Chip zwar komplizierter, aber Platz genug war ja da, da die Verkleinerung weiterhin voran schritt. Diese wichtigsten Tricks sind der Cache und die oben schon erwähnte spekulative Ausführung, die in engem Zusammenhang mit dem so genannten Pipeling steht. Auf diese Tricks gehen wir nun genauer ein.
Wie funktionieren die Tricks?
Caching
Der eine Trick ist so weit verbreitet und bekannt, dass ihn wohl keiner mehr als Trick ansieht, obwohl er es definitv ist: Caching. Der Trick besteht darin, so zu tun, als ob der Hauptspeicher schneller sei, als er wirklich ist. Deshalb werden Daten, die der Prozessor aus dem grossen Hauptspeicher lädt, zusätzlich im Prozessor noch in einem kleinen Zwischenspeicher (Cache) aufbewahrt. Die Erfahrung zeigt nämlich, dass viele Speicherinhalte mehrfach verwendet werden. Ab der zweiten Verwendung müssen sie aber nicht mehr aus dem langsamen Hauptspeicher geladen werden, sondern kommen aus dem viel schnelleren Cache: Es wird ein viel schnellerer Hauptspeicher vorgegaukelt. Dieser Zeitunterschied ist für ein Programm messbar und stellt für Schadsoftware eine wichtige Komponente des Angriffs dar.
Pipelining
Die ersten Computer funktionierten nach dem folgende einfachen, aber revolutionären Prinzip: Es werden der Reihe nach Befehle aus dem Hauptspeicher geladen und ausgeführt (grüner Ablauf). Seit gut 25 Jahren werden Befehle aber überlappend ausgeführt: Der nächste Befehl wird schon in Angriff genommen, bevor der vorherige fertig ist (blauer Ablauf, genannt Pipelining). Dem Programmierer wird aber nach wie vor vorgegaukelt, der Prozessor arbeite nach dem grünen Prinzip.
Pipelining ist vergleichbar mit der Herstellung von Autos am Fliessband: Der Zusammenbau eines einzelnen Autos dauert weiterhin mehrere Tage; trotzdem verlässt alle paar Minuten ein neues Auto die Produktionsstrasse. Ein riesiger Produktivitätsgewinn.
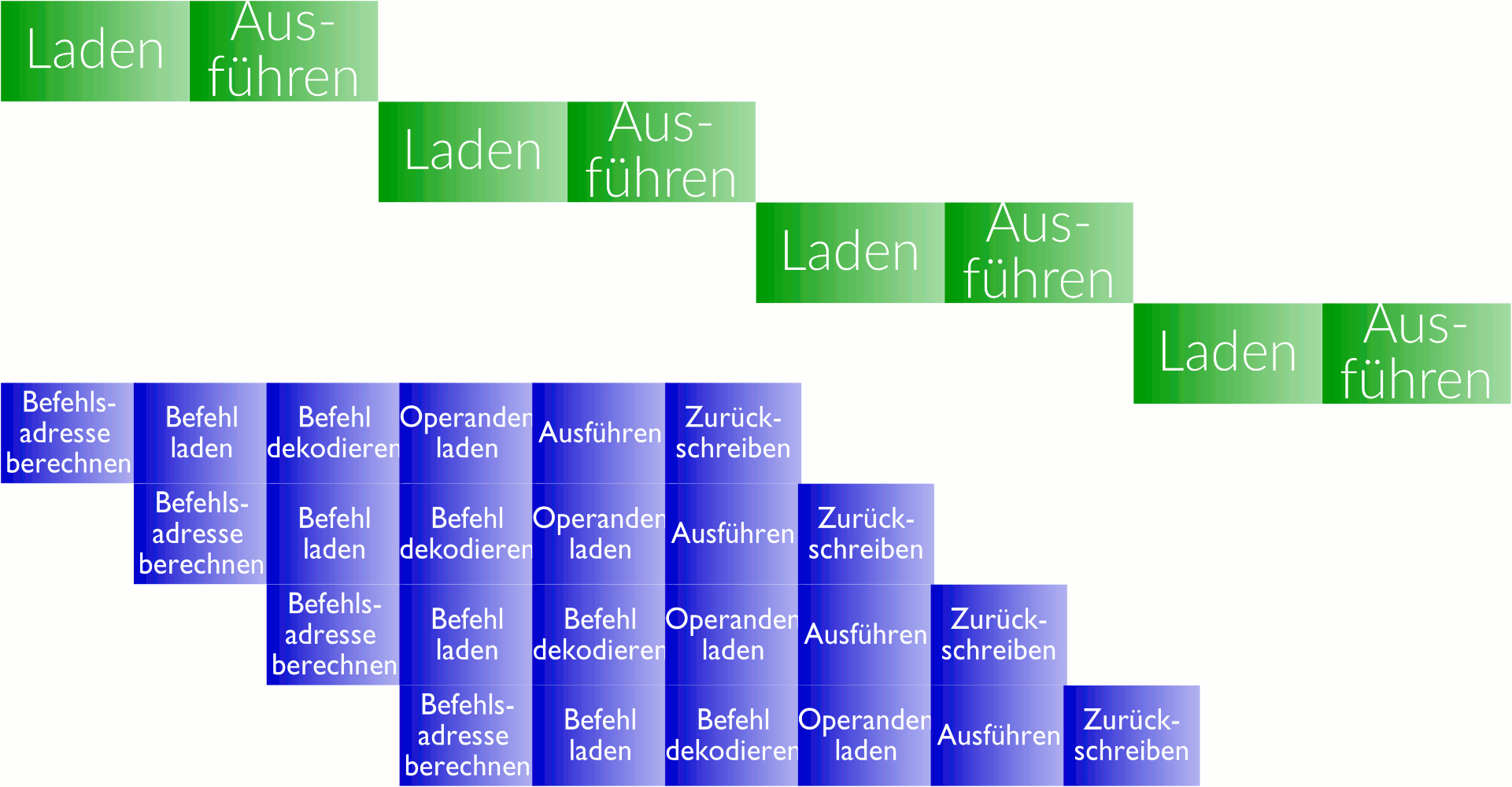
Pipelining ist vergleichbar mit der Herstellung von Autos am Fliessband: Der Zusammenbau eines einzelnen Autos dauert weiterhin mehrere Tage; trotzdem verlässt alle paar Minuten ein neues Auto die Produktionsstrasse. Ein riesiger Produktivitätsgewinn.
Dieses einfache Pipelining im Prozessor läuft gut, solange der Prozessor keine Entscheidungen treffen muss. Entscheidungen im Prozessor sind aber sehr häufig: Was macht der Benutzer gerade? Ist die Festplatte endlich bereit? Wo hat es noch Platz im Hauptspeicher? Ist die Eingabe gültig? Je nachdem, wie diese Entscheidung ausgeht, werden andere Befehle ab einer anderen Speicheradresse geladen und ausgeführt. Diese Änderung der Adresse, ab welcher der nächste Befehl ausgeführt wird, heisst „Sprung“.
Das heisst, das Pipelining im Prozessor unterscheidet sich in einer Beziehung grundlegen vom Montageband. Während beim Montageband jeder Schritt unabhängig vom nächsten ausgeführt wird, kann ein Befehl beim Prozessor alle nachgehenden Befehle verändern.
Pipelining im Prozessor unterscheidet sich aber in einer Beziehung grundlegend vom Montageband: Ein Produktionsschritt bei einem Auto kann bestimmen, dass alle nachfolgenden Autos ganz anders zusammengebaut werden sollen.
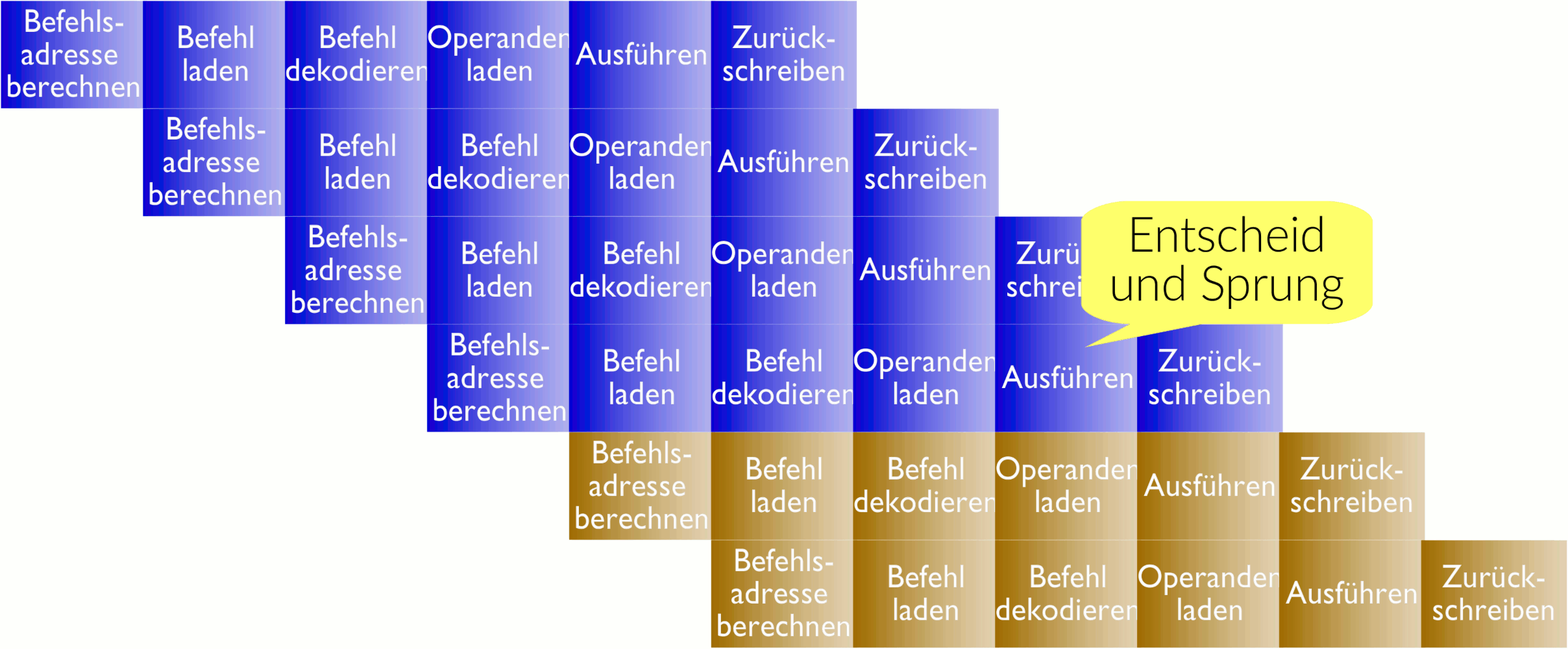
Zum Zeitpunkt der Ausführung des Sprungbefehls sind also schon viele andere Befehle (braun in der Grafik rechts) in der Pipeline. Solange aber nicht klar ist, ob sie ausgeführt werden sollen oder nicht, kann bei einer einfachen Pipeline gar nichts passieren: Der riesige Geschwindigkeitsvorteil durch die Pipeline ist bei jedem Sprungbefehl dahin.
Spekulative Ausführung
Seit bald 25 Jahren wird deshalb bei einem Sprungbefehl die Pipeline nicht leer gelassen, sondern der Prozessor versucht vorherzusagen, ob ein Sprung genommen werden soll oder nicht. Wenn die Vorhersage sich als richtig herausstellt, ist unser Prozessor viel schneller als nur mit Pipelining alleine und kann die Resultate der in der Zwischenzeit provisorisch durchgeführten Befehle behalten. Falls die Voraussage aber falsch war, müssen die Auswirkungen dieser schon provisorisch ausgeführten Befehle wieder rückgängig gemacht werden (Undo, Rollback). Daher erfolgt das Zurückschreiben nicht mehr direkt wie oben, sondern in einen internen Speicher, damit sie von nachfolgenden spekulativ ausgeführten Befehlen verwendet werden können. Erst wenn klar ist, dass diese Befehlskette auch wirklich ausgeführt werden soll, werden diese internen Zustände an die richtigen Stellen geschrieben; im anderen Fall wird dieser interne Zustand einfach weggeworfen. Diese Schlussphase wird als Pensionierung („retiring“) der Instruktion bezeichnet.

Schauen wir uns das Beispiel in der Grafik an: Der erste Befehl wird bearbeitet, muss aber beim Laden eines Wertes auf den langsamen Hauptspeicher warten. Der nächste Befehl ist ein Sprungbefehl, der vom Resultat der vorherigen Instruktion abhängt. Da dieses noch nicht bereit ist, gibt es eine Sprungvorhersage und die nachfolgenden Befehle werden spekulativ ausgeführt. Erst, wenn klar ist, ob diese Vorhersage richtig war, wird entschieden ob das interne Resultat weggeworfen oder offiziell wird.[3]Genau genommen ist nicht die spekulative Ausführung an sich das Problem, sondern wenn Befehle sich dabei — wie in der Grafik — gegenseitig überholen dürfen („out-of-order execution“, „instruction reordering“). Bei den meisten modernen Prozessoren sind Spekulation und Reordering aber gekoppelt.
2. Risiken und Nebenwirkungen
Angriffe
Die Angriffe nutzen nun aus, dass bei einem „Undo“ nicht der ganze Zustand wiederhergestellt wird, sondern der Cache auch weiterhin die Werte enthält, welche durch die spekulativ ausgeführten Instruktionen geladen wurden. Sie nutzen diese auf drei unterschiedliche Weisen.
Meltdown: Rechteanmassung
Ein Programm darf nicht auf den gesamten Speicher zugreifen, sondern nur auf Bereiche, die ihm auch zugewiesen wurden. Intel macht in seinen Prozessoren diese Überprüfung zu spät. Sie findet nämlich nicht dann statt, wenn die Daten für den Befehl („Operand“) geladen werden, sondern erst, wenn der Befehl in Pension gehen soll.
Dadurch kann ein böswilliger Programmierer in spekulativen Instruktionen auf Speicherbereiche zugreifen, die er sonst gar nicht zu sehen bekäme. Er kann das Resultat aber nicht verwenden, denn die Resultate des Befehls werden weggeworfen, sobald klar wird, dass die Vorhersage falsch war. Der Programmierer kann aber sein Programm anweisen, aufgrund des gelesenen Wertes in weiteren spekulativen Befehlen den Cache so zu verändern, dass in später wirklich ausgeführten Befehlen dann Rückschlüsse auf diese gelesenen Daten möglich sind.
Damit kann Speicher ausgelesen werden, auf den das Programm eigentlich gar nicht zugreifen dürfte. Da der Lesebefehl aber ja nicht wirklich (sonder nur spekulativ) ausgeführt wird, ist aus Sicht des Prozessors alles in Ordnung und er sieht keinen Grund, das dem Betriebssystem oder dem Benutzer mitzuteilen.
Damit lassen sich auf Intel-Prozessoren Speicherbereiche des Betriebssystems oder von anderen virtuellen Maschinen auslesen, eine Gefahr ganz besonders für alle Clouddienste.
Spectre 1: Indexgrenzenüberschreitung
Programme greifen regelmässig auf Felder (Arrays) zu: Sequenzen von Speicheradressen, die zusammengehörige Informationen enthalten und durch eine Startadresse und eine Länge definiert sind. Die einzelnen Positionen sind durchnummeriert (indexiert); nur Positionen bis zur maximalen Länge sind gültig.
Mittels zu grosser Indizes könnte auf Bereiche ausserhalb des Arrays zugegriffen werden, Bereiche, an denen sich andere Daten befinden. Deshalb finden—insbesondere in Programmen, die mit Indizes arbeiten, die von aussen beeinflusst werden können—Überprüfungen statt, ob der Index auch innerhalb des gültigen Bereichs liegt:
… vergleiche index, maximaler_index springe_wenn_grösser fehler_indexüberschreitung lade array[index], register_x … fehler_indexüberschreitung: # Fehlermeldung
Der Spectre-1-Angriff greift nun genau hier ein: Da im Normalfall der Index im gültigen Bereich liegt, prognostiziert der Prozessor, dass der lade-Befehl ausgeführt werden soll und liest spekulativ aus dem ungültigen Bereich. Obwohl der Fehler später bemerkt wird und der gelesene Wert nie in einem normal zugreifbaren Register landet: Der Cache bleibt verändert und lässt durch sein Verhalten Rückschlüsse wie oben zu.
Spectre 2: Unterjubeln von Befehlen
In vielen Programmen werden sogenannte Sprungtabellen verwendet: Die Adresse des nächsten auszuführenden Befehls steht an einer spezifischen oder zu berechnenden Speicheradresse. Betriebssysteme und objektorientierte Programmiersprachen sind zwei fleissige Nutzer dieser Technik.
Beim Spectre-2-Angriff wird der Prozessor so vorbereitet, dass die Sprungvorhersage auf einen vom Schadprogramm ausgewählten Codeblock zeigt. Auch hier werden die Befehle nur spekulativ ausgeführt, ihre Auswirkungen auf den Cache sind aber erkennbar.
Kernproblem
Das Kernproblem liegt darin, dass wir aus Effizienzgründen an vielen Stellen gemeinsame Ressourcen nutzen. Nicht nur im Prozessor gibt es solche gemeinsam genutzten Ressourcen, z.B. den Cache. Auch im Internet (gemeinsame Funkkanäle oder Leitungen) oder in der realen Welt (z.B. Schiene oder Strasse) gibt es unzählige davon. Wenn mehrere Teilnehmer eine gemeinsame Ressource nutzen, können sie darüber miteinander kommunizieren, beispielsweise indem der eine Teilnehmer die Auslastung dieser Ressource verändert und das Gegenüber diese Auslastung beobachtet. Damit wird diese Ressource zum (verdeckten) Kommunikationskanal.
Um diesen Kommunikationskanal zu nutzen, müssen beide Kommunikationspartner aktiv werden. Im Normalfall bedingt dies die freiwillige Teilnahme beider Seiten. Mittels Meltdown und Specter kann aber Schadsoftware bei spekulativer Ausführung (mit interner Umordnung der Befehle, „out-of-order execution“) eine der beiden Kommunikationsseiten quasi zur Zusammenarbeit übertölpelt werden. Damit bekommt die Spekulation ihre sichtbaren Nebenwirkungen.
Das Problem besteht nur, solange gemeinsame Ressourcen und spekulative Ausführung zusammen auftreten. Beide sind aber Schlüsselstellen für die Effizienz der heutigen Prozessoren. Durch bessere Trennung des Caches für normale und spekulative Instruktionen könnte das Problem gelöst werden.[4]Dies ist keine neue Technik; etwas sehr Ähnliches wird bereits verwendet beim spekulativen Ausführen von Befehlen, die Daten im Speicher ändern wollen. Durch die langen und teuren Entwicklungszyklen für Prozessoren werden wir erst in vielen Monaten mit Prozessoren rechnen dürfen, die das Problem nicht mehr haben.
Betroffen
- …von Meltdown sind laut aktuellem Informationsstand die meisten Intel-Prozessoren der letzten ca. 20 Jahre und einige neuere ARM-Prozessoren. Prozessoren anderer Hersteller, auch wenn sie x86-kompatibel sind, scheinen bisher nicht davon betroffen zu sein.
- …von Spectre 1 und 2 sind die meisten aktuellen Prozessoren, die spekulative Ausführung mit out-of-order execution verwenden, wenn auch in unterschiedlichem Ausmass. Insbesondere scheinen die meisten ARM-Prozessoren davon nicht betroffen zu sein. Insbesondere Spectre 1 scheint aber hauptsächlich Programme zu betreffen, die fremden Code ausführen. Prominente Beispiele sind da Webbrowser, die aber auch schon Gegenmassnahmen ergriffen haben.
Gegenmassnahmen
Alle drei Angriffe basieren auf Fehlern des Prozessors; da Updates bei Prozessoren jedoch schwierig sind und nur teilweise abhelfen, sind Betriebssysteme, Compiler und Anwendungsprogrammierer gefordert.
- Meltdown wird in vielen Betriebssystemen durch Änderung der Speicherorganisation verhindert. Bei jedem Betriebssystemaufruf sind neu teure Änderungen der Übersetzungstabelle notwendig. Dies führt jedoch zu Verlangsamungen, je nach Situation zwischen rund 5% und 30%, sehr selten bis fast 50%.
- Spectre 1 (Arraygrenzen) wird zuallererst die Programmierer beschäftigen. Sie müssen sicherstellen, dass—wenn sie nicht vertrauenswürdigen Code in ihrer Anwendung ausführen—dieser dann (a) den Seiteneffekt nicht auslösen oder (b) ihn nicht messen kann. Vermutlich werden in den nächsten Monaten findige Entwickler von Compilern Optionen schaffen, um diese Situation automatisch zu erkennen und zu verhindern.
Da die Lücke aber nur Anwendungen betrifft, die fremden Code ausführen (JIT, Bytecode und eventuell auch Interpreter), aber alle Anwendungen verlangsamen, werden die betroffenen Anwendungsentwickler diese Funktion des Compilers wahrscheinlich zuerst aktivieren müssen. - Spectre 2 (Berechnete Sprünge) wird aktuell über Microcode- in Kombination mit Betriebssystemupdates behoben. Alternativ kann auch sogenannter „RetPoline“-Code anstelle des berechneten Sprungs genutzt werden. Einige Compiler bieten bereits eine entsprechende Option an, weitere werden folgen.
Wir sehen, dass nur eine enge Kooperation aller Akteure (CPU-Hersteller, Betriebssystemmacher, Compilerentwickler und Anwendungsprogrammierer) das Problem nachhaltig lösen kann, zumindest solange keine Meltdown- und Spectre-sicheren neuen Prozessoren verfügbar sind.
Bis die Sache ausgestanden ist, werden auch die Nutzer stark gefordert: Das fleissige und zeitnahe Einspielen von Andwendungs-, Betriebssystem- und BIOS-/UEFI-Updates[5]Leider sind BIOS-/UEFI-Updates häufig nicht so einfach einzuspielen wie der Rest. Hier sind die Gerätehersteller gefordert. wie das Ausbaden unerwünschter Nebenwirkungen derselben werden dafür sorgen, dass uns allen über Monate hinweg nicht langweilig wird.
Weiterführende Informationen
Deutsch:
- FAQ zu Meltdown und Spectre (Heise), inklusive vielen Links
- Benchmarks (Heise)
- Deutsche Erklärung (Proact)
Englisch:
- Webseiten zu den Spectre– und Meltdown-Attacken inklusive technische/wissenschaftliche Literatur darin (aktuell sind die beiden Webseiten bis auf das Favicon identisch)
- Erste Hinweise auf ein Sicherheitsproblem (LWN)
- Performanceanalysen von Phoronix und Andreas Freund (Postgres)
- Erster Überblick über die Sicherheitslücke sowie Hintergründe und Entstehungsgeschichte (The Register)
- Englische Erläuterung, inklusive Begründung, wieso der Raspberry Pi nicht betroffen ist
- Beschreibung der Sicherheitslücken für Programmierer (Google)
- Test-Software, ob ein Linux-Rechner verwundbar ist
- Erläuterung zu RetPoline (Google)
- Caching war schon ein Problem in der Xbox 360
- Analyse von Prof. Steven Bellowin
Bildquellen
- Meltdown– und Spectre-Logos
- Schachspiel: Wikipedia-Eintrag „Chess“, Spiel zwischen Botvinnik und Yudovich (1933).
Ich danke Patrick Stählin (Schach), Matthias Fratz, Gaby Salvisberg und Marianne Jossen ganz herzlich für die vielen guten Ideen, Diskussionen, Feedbacks und Korrekturen.
Aktuelles zu IT-Sicherheit
- Die e-ID wird besser als versprochen
 Der Bund wird den Konsumentenschutz bei der e-ID noch verbessern. Vielen Dank!
Der Bund wird den Konsumentenschutz bei der e-ID noch verbessern. Vielen Dank! - Ransomware-sicheres Backup
 Cyberangriffe können verheerend sein. Doch ein letztes Sicherheitsnetz ist nicht so schwierig zu bauen. Hier die Hintergründe, was es beim Aufbau eines Ransomware-resilienten Backupprozesses zu beachten gilt.
Cyberangriffe können verheerend sein. Doch ein letztes Sicherheitsnetz ist nicht so schwierig zu bauen. Hier die Hintergründe, was es beim Aufbau eines Ransomware-resilienten Backupprozesses zu beachten gilt. - Löst die e-ID die Probleme von Jugendschutz und Privatsphäre?
 Heute gehen wir der Frage nach, ob eine e-ID unsere gesellschaftlichen Probleme im Internet lösen kann. Und wie wir zu einer besseren Lösung kommen.
Heute gehen wir der Frage nach, ob eine e-ID unsere gesellschaftlichen Probleme im Internet lösen kann. Und wie wir zu einer besseren Lösung kommen. - 📻 E-ID: Kollidiert Altersverifikation mit dem Recht auf Anonymität?
 Die e-ID ist aktuell auch im rund um Altersverifikation in Diskussion. In einem Interview mit Radio SRF versuchte ich, einige Punkte zu klären.
Die e-ID ist aktuell auch im rund um Altersverifikation in Diskussion. In einem Interview mit Radio SRF versuchte ich, einige Punkte zu klären. - Ja zur E-ID
 Ich setze mich bekanntermassen sehr für IT-Sicherheit und Privatsphäre ein. Und genau deshalb finde ich die E-ID in ihrer jetzt geplanten Form eine ganz wichtige Zutat. Hier meine Gründe für ein Ja am 28. September. Zusammen… Ja zur E-ID weiterlesen
Ich setze mich bekanntermassen sehr für IT-Sicherheit und Privatsphäre ein. Und genau deshalb finde ich die E-ID in ihrer jetzt geplanten Form eine ganz wichtige Zutat. Hier meine Gründe für ein Ja am 28. September. Zusammen… Ja zur E-ID weiterlesen - CH-Journi-Starterpack fürs Fediverse
 Im gestrigen Artikel rund ums Fediverse – das offene, föderierte soziale Netzwerk – hatte ich euch ein Starterpack versprochen. Hier ist es und bringt euch deutschsprachige Journalistinnen, Journalisten und Medien aus der Schweiz und für… CH-Journi-Starterpack fürs Fediverse weiterlesen
Im gestrigen Artikel rund ums Fediverse – das offene, föderierte soziale Netzwerk – hatte ich euch ein Starterpack versprochen. Hier ist es und bringt euch deutschsprachige Journalistinnen, Journalisten und Medien aus der Schweiz und für… CH-Journi-Starterpack fürs Fediverse weiterlesen - Föderalismus auch bei sozialen Netzen
 Föderalismus liegt uns im Blut. Unsere gesamte Gesellschaft ist föderal aufgebaut. Aber – wieso lassen wir uns dann bei sogenannten «sozialen», also gesellschaftlichen, Netzen auf zentralistische Player mit absoluter Macht ein? In den digitalen gesellschaftlichen… Föderalismus auch bei sozialen Netzen weiterlesen
Föderalismus liegt uns im Blut. Unsere gesamte Gesellschaft ist föderal aufgebaut. Aber – wieso lassen wir uns dann bei sogenannten «sozialen», also gesellschaftlichen, Netzen auf zentralistische Player mit absoluter Macht ein? In den digitalen gesellschaftlichen… Föderalismus auch bei sozialen Netzen weiterlesen - Unterschreiben gegen mehr Überwachung
 Der Bundesrat will auf dem Verordnungsweg den Überwachungsstaat massiv ausbauen und die Schweizer IT-Wirtschaft im Vergleich zu ausländischen Anbieter schlechter stellen. Deine Unterschrift unter der Petition hilft!
Der Bundesrat will auf dem Verordnungsweg den Überwachungsstaat massiv ausbauen und die Schweizer IT-Wirtschaft im Vergleich zu ausländischen Anbieter schlechter stellen. Deine Unterschrift unter der Petition hilft! - Sichere VoIP-Telefone: Nein, danke‽
 Zumindest war dies das erste, was ich dachte, als ich hörte, dass der weltgrösste Hersteller von Schreibtischtelefonen mit Internetanbindung, Yealink, es jedem Telefon ermöglicht, sich als beliebiges anderes Yealink-Telefon auszugeben. Und somit als dieses Telefonate… Sichere VoIP-Telefone: Nein, danke‽ weiterlesen
Zumindest war dies das erste, was ich dachte, als ich hörte, dass der weltgrösste Hersteller von Schreibtischtelefonen mit Internetanbindung, Yealink, es jedem Telefon ermöglicht, sich als beliebiges anderes Yealink-Telefon auszugeben. Und somit als dieses Telefonate… Sichere VoIP-Telefone: Nein, danke‽ weiterlesen - Diceware: Sicher & deutsch
 Diceware ist, laut Wikipedia, «eine einfache Methode, sichere und leicht erinnerbare Passwörter und Passphrasen mithilfe eines Würfels zu erzeugen». Auf der Suche nach einem deutschsprachigen Diceware-Generator habe ich keinen gefunden, der nur im Browser läuft,… Diceware: Sicher & deutsch weiterlesen
Diceware ist, laut Wikipedia, «eine einfache Methode, sichere und leicht erinnerbare Passwörter und Passphrasen mithilfe eines Würfels zu erzeugen». Auf der Suche nach einem deutschsprachigen Diceware-Generator habe ich keinen gefunden, der nur im Browser läuft,… Diceware: Sicher & deutsch weiterlesen - Nextcloud: Automatischer Upload auf Android verstehen
 Ich hatte das Gefühl, dass der automatische Upload auf Android unzuverlässig sei, konnte das aber nicht richtig festmachen. Jetzt weiss ich wieso und was dabei hilft.
Ich hatte das Gefühl, dass der automatische Upload auf Android unzuverlässig sei, konnte das aber nicht richtig festmachen. Jetzt weiss ich wieso und was dabei hilft. - VÜPF: Staatliche Überwachungsfantasien im Realitätscheck
 Die Revision der «Verordnung über die Überwachung des Post- und Fernmeldeverkehrs» (VÜPF) schreckte die Schweiz spät auf. Am Wochenende publizierte die NZZ ein Streitgespräch zum VÜPF. Darin findet sich vor allem ein Absatz des VÜPF-Verschärfungs-Befürworters… VÜPF: Staatliche Überwachungsfantasien im Realitätscheck weiterlesen
Die Revision der «Verordnung über die Überwachung des Post- und Fernmeldeverkehrs» (VÜPF) schreckte die Schweiz spät auf. Am Wochenende publizierte die NZZ ein Streitgespräch zum VÜPF. Darin findet sich vor allem ein Absatz des VÜPF-Verschärfungs-Befürworters… VÜPF: Staatliche Überwachungsfantasien im Realitätscheck weiterlesen - Phishing-Trend Schweizerdeutsch
 Spam und Phishingversuche auf Schweizerdeutsch scheinen beliebter zu werden. Wieso nutzen Spammer denn diese Nischensprache? Schauen wir in dieser kleinen Weiterbildung in Sachen Spam und Phishing zuerst hinter die Kulissen der Betrüger, um ihre Methoden… Phishing-Trend Schweizerdeutsch weiterlesen
Spam und Phishingversuche auf Schweizerdeutsch scheinen beliebter zu werden. Wieso nutzen Spammer denn diese Nischensprache? Schauen wir in dieser kleinen Weiterbildung in Sachen Spam und Phishing zuerst hinter die Kulissen der Betrüger, um ihre Methoden… Phishing-Trend Schweizerdeutsch weiterlesen - Persönliche Daten für Facebook-KI
 Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle Beiträge (auch die zutiefst persönlichen),… Persönliche Daten für Facebook-KI weiterlesen
Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle Beiträge (auch die zutiefst persönlichen),… Persönliche Daten für Facebook-KI weiterlesen - In den Klauen der Cloud
 Bert Hubert, niederländischer Internetpionier und Hansdampf-in-allen-Gassen, hat einen grossartigen Artikel geschrieben, in dem er die Verwirrung rund um «in die Cloud gehen» auflöst. Ich habe ihn für DNIP auf Deutsch übersetzt.
Bert Hubert, niederländischer Internetpionier und Hansdampf-in-allen-Gassen, hat einen grossartigen Artikel geschrieben, in dem er die Verwirrung rund um «in die Cloud gehen» auflöst. Ich habe ihn für DNIP auf Deutsch übersetzt. - Können KI-Systeme Artikel klauen?
 Vor ein paar Wochen hat die NZZ einen Artikel veröffentlicht, in dem Petra Gössi das NZZ-Team erschreckte, weil via KI-Chatbot angeblich «beinahe der gesamte Inhalt des Artikels […] in der Antwort von Perplexity zu lesen»… Können KI-Systeme Artikel klauen? weiterlesen
Vor ein paar Wochen hat die NZZ einen Artikel veröffentlicht, in dem Petra Gössi das NZZ-Team erschreckte, weil via KI-Chatbot angeblich «beinahe der gesamte Inhalt des Artikels […] in der Antwort von Perplexity zu lesen»… Können KI-Systeme Artikel klauen? weiterlesen - Was Prozessoren und die Frequenzwand mit der Cloud zu tun haben
 Seit bald 20 Jahren werden die CPU-Kerne für Computer nicht mehr schneller. Trotzdem werden neue Prozessoren verkauft. Und der Trend geht in die Cloud. Wie das zusammenhängt.
Seit bald 20 Jahren werden die CPU-Kerne für Computer nicht mehr schneller. Trotzdem werden neue Prozessoren verkauft. Und der Trend geht in die Cloud. Wie das zusammenhängt. - Facebook: Moderation für Geschäftsinteressenmaximierung, nicht für das Soziale im Netz
 Hatte mich nach wahrscheinlich mehr als einem Jahr mal wieder bei Facebook eingeloggt. Das erste, was mir entgegenkam: Offensichtlicher Spam, der mittels falscher Botschaften auf Klicks abzielte. Aber beim Versuch, einen wahrheitsgemässen Bericht über ein… Facebook: Moderation für Geschäftsinteressenmaximierung, nicht für das Soziale im Netz weiterlesen
Hatte mich nach wahrscheinlich mehr als einem Jahr mal wieder bei Facebook eingeloggt. Das erste, was mir entgegenkam: Offensichtlicher Spam, der mittels falscher Botschaften auf Klicks abzielte. Aber beim Versuch, einen wahrheitsgemässen Bericht über ein… Facebook: Moderation für Geschäftsinteressenmaximierung, nicht für das Soziale im Netz weiterlesen - Was verraten KI-Chatbots?
 «Täderlät» die KI? Vor ein paar Wochen fragte mich jemand besorgt, ob man denn gar nichts in Chatbot-Fenster eingeben könne, was man nicht auch öffentlich teilen würde. Während der Erklärung fiel mir auf, dass ganz… Was verraten KI-Chatbots? weiterlesen
«Täderlät» die KI? Vor ein paar Wochen fragte mich jemand besorgt, ob man denn gar nichts in Chatbot-Fenster eingeben könne, was man nicht auch öffentlich teilen würde. Während der Erklärung fiel mir auf, dass ganz… Was verraten KI-Chatbots? weiterlesen - Sicherheit versteckt sich gerne
 Wieso sieht man einer Firma nicht von aussen an, wie gut ihre IT-Sicherheit ist? Einige Überlegungen aus Erfahrung.
Wieso sieht man einer Firma nicht von aussen an, wie gut ihre IT-Sicherheit ist? Einige Überlegungen aus Erfahrung. - Chatkontrolle: Schöner als Fiktion
 Wir kennen «1984» nicht, weil es eine technische, objektive Abhandlung war. Wir erinnern uns, weil es eine packende, düstere, verstörende Erzählung ist.
Wir kennen «1984» nicht, weil es eine technische, objektive Abhandlung war. Wir erinnern uns, weil es eine packende, düstere, verstörende Erzählung ist. - Chatkontrolle, die Schweiz und unsere Freiheit
 In der EU wird seit vergangenem Mittwoch wieder über die sogenannte «Chatkontrolle» verhandelt. Worum geht es da? Und welche Auswirkungen hat das auf die Schweiz?
In der EU wird seit vergangenem Mittwoch wieder über die sogenannte «Chatkontrolle» verhandelt. Worum geht es da? Und welche Auswirkungen hat das auf die Schweiz? - Cloudspeicher sind nicht (immer) für die Ewigkeit
 Wieder streicht ein Cloudspeicher seine Segel. Was wir daraus lernen sollten.
Wieder streicht ein Cloudspeicher seine Segel. Was wir daraus lernen sollten. - IT sind nicht nur Kosten
 Oft wird die ganze IT-Abteilung aus Sicht der Geschäftsführung nur als Kostenfaktor angesehen. Wer das so sieht, macht es sich zu einfach.
Oft wird die ganze IT-Abteilung aus Sicht der Geschäftsführung nur als Kostenfaktor angesehen. Wer das so sieht, macht es sich zu einfach. - CrowdStrike, die Dritte
 In den 1½ Wochen seit Publikation der ersten beiden Teile hat sich einiges getan. Microsoft liess es sich nicht nehmen, die Schuld am Vorfall der EU in die Schuhe zu schieben, wie das Apple mit… CrowdStrike, die Dritte weiterlesen
In den 1½ Wochen seit Publikation der ersten beiden Teile hat sich einiges getan. Microsoft liess es sich nicht nehmen, die Schuld am Vorfall der EU in die Schuhe zu schieben, wie das Apple mit… CrowdStrike, die Dritte weiterlesen - Unnützes Wissen zu CrowdStrike
 Ich habe die letzten Wochen viele Informationen zu CrowdStrike zusammengetragen und bei DNIP veröffentlicht. Hier ein paar Punkte, die bei DNIP nicht gepasst hätten. Einiges davon ist sinnvolles Hintergrundwissen, einiges taugt eher als Anekdote für… Unnützes Wissen zu CrowdStrike weiterlesen
Ich habe die letzten Wochen viele Informationen zu CrowdStrike zusammengetragen und bei DNIP veröffentlicht. Hier ein paar Punkte, die bei DNIP nicht gepasst hätten. Einiges davon ist sinnvolles Hintergrundwissen, einiges taugt eher als Anekdote für… Unnützes Wissen zu CrowdStrike weiterlesen - Marcel pendelt zwischem Spam und Scam
 Beim Pendeln hatte ich viel Zeit. Auch um Mails aus dem Spamordner zu lesen. Hier ein paar Dinge, die man daraus lernen kann. Um sich und sein Umfeld zu schützen.
Beim Pendeln hatte ich viel Zeit. Auch um Mails aus dem Spamordner zu lesen. Hier ein paar Dinge, die man daraus lernen kann. Um sich und sein Umfeld zu schützen. - Die NZZ liefert Daten an Microsoft — und Nein sagen ist nicht
 Die andauernden CookieBanner nerven. Aber noch viel mehr nervt es, wenn in der Liste von „800 sorgfältig ausgewählten Werbepartnern (oder so)“ einige Schalter fix auf „diese Werbe-/Datenmarketingplattform darf immer Cookies setzen, so sehr ihr euch… Die NZZ liefert Daten an Microsoft — und Nein sagen ist nicht weiterlesen
Die andauernden CookieBanner nerven. Aber noch viel mehr nervt es, wenn in der Liste von „800 sorgfältig ausgewählten Werbepartnern (oder so)“ einige Schalter fix auf „diese Werbe-/Datenmarketingplattform darf immer Cookies setzen, so sehr ihr euch… Die NZZ liefert Daten an Microsoft — und Nein sagen ist nicht weiterlesen - «CrowdStrike»: Ausfälle verstehen und vermeiden
 Am Freitag standen in weiten Teilen der Welt Millionen von Windows-Rechnern still: Bancomaten, Lebensmittelgeschäfte, Flughäfen, Spitäler uvam. waren lahmgelegt. Die Schweiz blieb weitgehend nur verschont, weil sie noch schlief. Ich schaue hinter die Kulissen und… «CrowdStrike»: Ausfälle verstehen und vermeiden weiterlesen
Am Freitag standen in weiten Teilen der Welt Millionen von Windows-Rechnern still: Bancomaten, Lebensmittelgeschäfte, Flughäfen, Spitäler uvam. waren lahmgelegt. Die Schweiz blieb weitgehend nur verschont, weil sie noch schlief. Ich schaue hinter die Kulissen und… «CrowdStrike»: Ausfälle verstehen und vermeiden weiterlesen - Auch du, mein Sohn Firefox
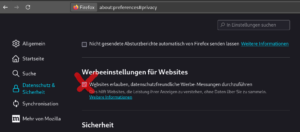 Ich habe bisher immer Firefox empfohlen, weil seine Standardeinstellungen aus Sicht der Privatsphäre sehr gut waren, im Vergleich zu den anderen „grossen Browsern“. Das hat sich geändert. Leider. Was wir jetzt tun sollten.
Ich habe bisher immer Firefox empfohlen, weil seine Standardeinstellungen aus Sicht der Privatsphäre sehr gut waren, im Vergleich zu den anderen „grossen Browsern“. Das hat sich geändert. Leider. Was wir jetzt tun sollten.





Schreibe einen Kommentar