Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude.
Ungenauigkeit voraus!
Die Hersteller von KI-Chatbots halten sich inzwischen sehr zurück mit Details. Dies ist deshalb eine Extrapolation aus öffentlich verfügbaren Informationen. Falls ich irgendwo falsch liege, freue ich mich über zusätzliche Hinweise oder Korrekturen.
Aber als Überblick und ersten Eindruck ist es ein guter Start.
Der LLM-Datenlebenszyklus
Diese Grafik ist die Basis der folgenden Erklärungen. Sie müssen Sie jetzt noch nicht verstehen.

Der normale Chat
Für uns Normalnutzer:innen ist der kleine Bereich oben rechts um den kleinen hellblauen Doppelpfeil (beschriftet „Chatfragen“) interessant: Aus unserer aktuelle Frage („Prompt“, das „Q-A-Q“-Dokument) wird zusammen mit den Informationen aus dem KI-Sprachmodell (Large Language Model, die „LLM“-Box in der Mitte mit den symbolischen Statistik-Kurven) eine Antwort generiert („Q-A-Q-A“-Box, unser Chat, nun aber mit einer Antwort).
Mehr wissen: Den Trainingsprozess- und Antwortprozess bei ChatGPT und wieso die Beantwortung auf Zufallszahlen beruht habe ich bei DNIP schon detaillierter beschrieben.
Wie aber kommt das LLM zu seinen Informationen?
Lernschritt 1: Sprache und Fakten
Aus dem Internet, sozialen Medien sowie anderen Kanälen werden möglichst viele Texte extrahiert („crawled“), wogegen man sich nur schwer wehren kann. Diese werden dann in kurze Bruchstücke geschreddert und aus diesen werden automatisiert Muster extrahiert. Dies ist der Trainingsprozess. Um zu sehen, ob der Trainingsprozess erfolgreich ist, wird ein Teil der ursprünglichen Daten nicht für den Trainingsprozess genutzt, sondern nur, um zu sehen, wie das System darauf reagiert („Testdaten“).
Das Sprachmodell („LLM“) hat nun in verschiedenen Sprachen Muster für Wörter, Sätze, Absätzen und Artikelstrukturen extrahiert und in seiner Statistik („Parametern“) gespeichert. Darunter sind auch viele Fakten, aber auch Vorurteile, Falschaussagen oder schlichtweg Ironie (welche oft nicht als solche verstanden wird.
Mehr wissen: Zur Datenherkunft, dem grundlegenden KI-Trainingsprozess im Allgemeinen sowie dem Trainingsprozess bei ChatGPT im Speziellen habe ich bei DNIP schon Artikel geschrieben. Zu den Schwierigkeiten, seine Webseite vor der Nutzung durch KI zu schützen oder Daten wieder aus KI-Systemen gelöscht zu bekommen, habe ich auf Englisch bei Netfuture.ch geschrieben.
Lernschritt 2: Fragen beantworten
Nach Lernschritt 1 können LLMs wie ChatGPT erst Sätze etc. vervollständigen. Damit sie auch Fragen beantworten oder sonstige Problemstellungen lösen (Texte kürzen, Listen von Argumenten liefern, …) können, müssen sie die dazu nötigen Muster erst trainiert bekommen.
Dazu erzeugt zuerst der Mensch links oben Frage-Antwort-Pärchen (das „Q+A“-Dokument in der obigen Grafik) oder sonstige Anfragen-Lösungen-Pärchen. Auch hier wird wieder ein kleiner Teil als Testdaten für später beiseite gelegt. Mit den Rest werden jetzt diese Dialogmuster eintrainiert. Wenn die entsprechenden Muster jetzt auch im LLM-Statistikspeicher abgelegt sind, dann kann der Chatbot die Anfragen mit Antworten vervollständigen.
Sprachmodelle brauchen zum Training unzählige Varianten von Formulierungen, bis die Muster genügend eintrainiert sind — viel mehr als beispielsweise Kinder. Da dies Menschen irgendwann langweilig wird (und der Firma zu teuer), wurde das LLM genutzt, um aus diesen Pärchen noch weitere Varianten zu erzeugen. Menschen wurden nur noch eingesetzt, um die Bewertung dieser generierten Pärchen zu übernehmen. Noch später wurde auch die Bewertung automatisiert und nur noch die korrekte Bewertung anhand von Stichproben überprüft. Dieser Vorgang nennt sich «Reinforcement learning from human feedback» (RLHF; zu Deutsch etwa: Bestärkendes Lernen durch menschliche Rückkoppelung) und wird durch die zentrale grüne Rückkoppelungsschleife dargestellt.
Mehr wissen: Das z.T. dramatische Schicksal der Menschen in diesen KI-Testschleifen hat beispielsweise der Guardian beschrieben. Einige Beispiele, wo das Training (z.T. peinlich) versagt hat, finden sich z.B. hier.
Lernschritt 3: Aus Fehlern lernen
Nicht immer werden die richtigen Muster angewandt. Von einer der ersten Versionen von ChatGPT stammt folgendes Beispiel, wo fälschlicherweise das Frage-Antwort-Muster «Dreisatz lösen» erkannt und vervollständigt wurde.
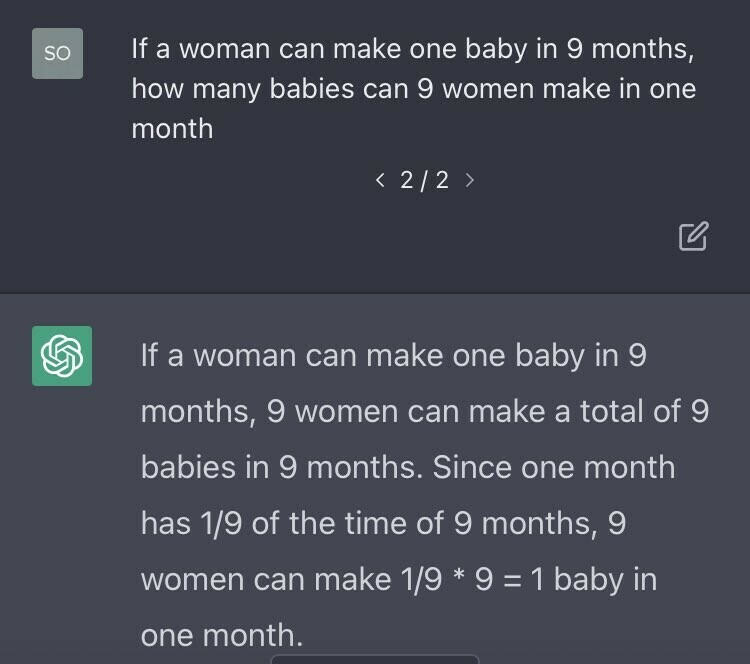
Das hat natürlich damals unter den Geeks Gelächter verursacht und bei OpenAI ein paar rote Köpfe. Entsprechend wollte man dafür sorgen, dass solche Antworten zukünftig nicht mehr auftauchten.
Der KI-Ansatz dafür ist: Wir müssen die Muster zu Schwangerschaften stärken, damit bei solchen Fragen das Muster «Schwangerschaftsdauer» Oberhand gewinnt über «Dreisatz lösen». Natürlich könnte OpenAI nun die Menschen links oben in der Grafik dafür bezahlen, mehr Muster zu Schwangerschaften zu produzieren und den Lernschritt 2 (RLHF) zu durchlaufen. Das wurde wahrscheinlich auch gemacht. Das war aber mutmasslich nur ein Teil der Lösung.
Denn Menschen, die schon tausende von solchen Pärchen produziert haben, sind irgendwann in einem Trott angekommen: Sie liefern keine vollständig neuen, innovativen Muster mehr. Viel interessanter wird es, wenn eine KI-Firma solche Pärchen „crowdsourcen“ kann, also die Ideenvielfalt der gesamten Menschheit ausnutzen kann.
Oder, in diesem Fall, ihrer Nutzerbasis. Die KI-Chatbot-Nutzer:innen haben viele Ideen; stellen Dreisatz- oder Schwangerschaftsfragen auf viele verschiedene Art und Weise. Und deshalb sind Chats zu Dreisatz und/oder Schwangerschaft eine wertvoller Schatz an möglichen Fragestellungen, welche der Chatbot in der nächsten Version zuverlässig richtig beantworten können sollte.
Deshalb ist zu erwarten, dass die KI-Firmen dann die Chats ihrer Nutzer — sofern das in ihren AGBs vorgesehen war — nach solchen Dialogen durchkämmt haben und — wie schon in den Lernschritten 1 und 2 — einen Teil davon als Trainingsmaterial und einen Teil davon zum Testen genutzt haben, ob auch zuverlässig die richtige Fragestellung käme.
Mehr wissen: Dass die Ausgaben zufällig sind, wird im Rahmen der Erklärung der ChatGPT-Funktionsweise erklärt, aber auch beim Thema «Zufall» nochmals aufgegriffen und stärker motiviert. Wieso man Fehler (u.a. aufgrund dieses Zufalls) nie ganz eliminieren kann, erkläre ich im Artikel über das «Recht auf Vergessenwerden», welches sich mit KI-Systemen beisst. Die Herkunft dieser Nutzerdaten wird im Artikel über die dunkle Datenherkunft thematisiert.
Künstliche Intelligenz
News (mehr…)
- «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich
 Forschende der Uni Zürich haben KI-Bots in ein Forum der Plattform Reddit eingeschleust. Und zwar ohne Wissen der Betreiber:innen und… «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich weiterlesen
Forschende der Uni Zürich haben KI-Bots in ein Forum der Plattform Reddit eingeschleust. Und zwar ohne Wissen der Betreiber:innen und… «Reddit rAIngelegt»: Hörkombinat-Podcast-Interview zur fragwürdigen KI-Manipulation an der Universität Zürich weiterlesen - Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView»
 Wie DNIP.ch am Montag als erstes Medium berichtete, hat eine Forschungsgruppe mit Anbindung zur Universität Zürich mittels KI psychologische Forschung… Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView» weiterlesen
Wie DNIP.ch am Montag als erstes Medium berichtete, hat eine Forschungsgruppe mit Anbindung zur Universität Zürich mittels KI psychologische Forschung… Forschung am Menschen ohne deren Wissen: Universität Zürich und Reddit «r/ChangeMyView» weiterlesen - KI-Webseiten petzen und beeinflussen
 Klar kann man die KI manchmal zu verräterischem Verhalten verleiten. Aber noch einfacher ist es, wenn die Webseite ihre Anweisungen… KI-Webseiten petzen und beeinflussen weiterlesen
Klar kann man die KI manchmal zu verräterischem Verhalten verleiten. Aber noch einfacher ist es, wenn die Webseite ihre Anweisungen… KI-Webseiten petzen und beeinflussen weiterlesen
Lange Artikel (mehr…)
- Persönliche Daten für Facebook-KI
 Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle… Persönliche Daten für Facebook-KI weiterlesen
Meta – Zuckerbergs Imperium hinter Facebook, WhatsApp, Instagram, Threads etc. – hat angekündigt, ab 27. Mai die persönlichen Daten seiner Nutzer:innen in Europa für KI-Training zu verwenden. Dazu gehören alle… Persönliche Daten für Facebook-KI weiterlesen - KI-Datenkreisläufe
 Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude. Ungenauigkeit voraus! Die Hersteller von KI-Chatbots halten… KI-Datenkreisläufe weiterlesen
Hier ein kleiner Überblick über die Datenkreisläufe rund um generative KI, insbesondere grosse Sprachmodelle (Large Language Model, LLM) wie ChatGPT, Gemini oder Claude. Ungenauigkeit voraus! Die Hersteller von KI-Chatbots halten… KI-Datenkreisläufe weiterlesen - Der Homo Ludens muss Werkzeuge spielend erfahren. Auch KI
 Fast alle Werkzeuge, die wir «spielend» beherrschen, haben wir spielend gelernt. Das sollten wir auch bei generativer KI.
Fast alle Werkzeuge, die wir «spielend» beherrschen, haben wir spielend gelernt. Das sollten wir auch bei generativer KI. - Der Turing-Test im Laufe der Zeit
 Vor einem knappen Jahrhundert hat sich Alan Turing mit den Fundamenten der heutigen Informatik beschäftigt: Kryptographie, Komplexität/Rechenaufwand, aber auch, ob und wie wir erkennen könnten, ob Computer „intelligent“ seien. Dieses… Der Turing-Test im Laufe der Zeit weiterlesen
Vor einem knappen Jahrhundert hat sich Alan Turing mit den Fundamenten der heutigen Informatik beschäftigt: Kryptographie, Komplexität/Rechenaufwand, aber auch, ob und wie wir erkennen könnten, ob Computer „intelligent“ seien. Dieses… Der Turing-Test im Laufe der Zeit weiterlesen - «QualityLand» sagt die Gegenwart voraus und erklärt sie
 Ich habe vor Kurzem das Buch «QualityLand» von Marc-Uwe Kling von 2017 in meinem Büchergestell gefunden. Und war erstaunt, wie akkurat es die Gegenwart erklärt. Eine Leseempfehlung.
Ich habe vor Kurzem das Buch «QualityLand» von Marc-Uwe Kling von 2017 in meinem Büchergestell gefunden. Und war erstaunt, wie akkurat es die Gegenwart erklärt. Eine Leseempfehlung. - Neuralink ist (noch) keine Schlagzeile wert
 Diese Woche haben einige kurze Tweets von Elon Musk hunderte oder gar tausende von Artikeln ausgelöst. Wieso?
Diese Woche haben einige kurze Tweets von Elon Musk hunderte oder gar tausende von Artikeln ausgelöst. Wieso? - «Quasselquote» bei LLM-Sprachmodellen
 Neulich erwähnte jemand, dass man ChatGPT-Output bei Schülern häufig an der «Quasselquote» erkennen könne. Das ist eine Nebenwirkung der Funktionsweise dieser Sprachmodelle, aber natürlich noch kein Beweis. Etwas Hintergrund.
Neulich erwähnte jemand, dass man ChatGPT-Output bei Schülern häufig an der «Quasselquote» erkennen könne. Das ist eine Nebenwirkung der Funktionsweise dieser Sprachmodelle, aber natürlich noch kein Beweis. Etwas Hintergrund. - «KI» und «Vertrauen»: Passt das zusammen?
 Vor einigen Wochen hat Bruce Schneier einen Vortrag gehalten, bei dem er vor der der Vermischung und Fehlinterpretation des Begriffs «Vertrauen» gewarnt hat, ganz besonders beim Umgang mit dem, was… «KI» und «Vertrauen»: Passt das zusammen? weiterlesen
Vor einigen Wochen hat Bruce Schneier einen Vortrag gehalten, bei dem er vor der der Vermischung und Fehlinterpretation des Begriffs «Vertrauen» gewarnt hat, ganz besonders beim Umgang mit dem, was… «KI» und «Vertrauen»: Passt das zusammen? weiterlesen - Wegweiser für generative KI-Tools
 Es gibt inzwischen eine grosse Anzahl generativer KI-Tools, nicht nur für den Unterricht. Hier ein Überblick über verschiedene Tool-Sammlungen.
Es gibt inzwischen eine grosse Anzahl generativer KI-Tools, nicht nur für den Unterricht. Hier ein Überblick über verschiedene Tool-Sammlungen. - KI-Vergiftung
 Eine aggressive Alternative zur Blockade von KI-Crawlern ist das «Vergiften» der dahinterliegenden KI-Modelle. Was bedeutet das?
Eine aggressive Alternative zur Blockade von KI-Crawlern ist das «Vergiften» der dahinterliegenden KI-Modelle. Was bedeutet das? - Lehrerverband, ChatGPT und Datenschutz
 Der Dachverband der Lehrerinnen und Lehrer (LCH) sei besorgt, dass es in der Schweiz keine einheitliche Regelung gäbe, wie Lehrpersonen mit Daten ihrer Schützlinge umgehen sollen und ob sie dafür… Lehrerverband, ChatGPT und Datenschutz weiterlesen
Der Dachverband der Lehrerinnen und Lehrer (LCH) sei besorgt, dass es in der Schweiz keine einheitliche Regelung gäbe, wie Lehrpersonen mit Daten ihrer Schützlinge umgehen sollen und ob sie dafür… Lehrerverband, ChatGPT und Datenschutz weiterlesen - Goethe oder GPThe?
 In «Wie funktioniert ChatGPT?» habe ich die Experimente von Andrej Karpathy mit Shakespeare-Texten wiedergegeben. Aber funktioniert das auch auf Deutsch? Zum Beispiel mit Goethe? Finden wir es heraus!
In «Wie funktioniert ChatGPT?» habe ich die Experimente von Andrej Karpathy mit Shakespeare-Texten wiedergegeben. Aber funktioniert das auch auf Deutsch? Zum Beispiel mit Goethe? Finden wir es heraus! - KI: Alles nur Zufall?
 Wer von einer «Künstlichen Intelligenz» Texte oder Bilder erzeugen lässt, weiss, dass das Resultat stark auf Zufall beruht. Vor Kurzem erschien in der NZZ ein Beitrag, der die Unzuverlässigkeit der… KI: Alles nur Zufall? weiterlesen
Wer von einer «Künstlichen Intelligenz» Texte oder Bilder erzeugen lässt, weiss, dass das Resultat stark auf Zufall beruht. Vor Kurzem erschien in der NZZ ein Beitrag, der die Unzuverlässigkeit der… KI: Alles nur Zufall? weiterlesen - Hype-Tech
 Wieso tauchen gewisse Hype-Themen wie Blockchain oder Maschinelles Lernen/Künstliche Intelligenz regelmässig in IT-Projekten auf, obwohl die Technik nicht wirklich zur gewünschten Lösung passt? Oder es auch einfachere, bessere Ansätze gäbe?
Wieso tauchen gewisse Hype-Themen wie Blockchain oder Maschinelles Lernen/Künstliche Intelligenz regelmässig in IT-Projekten auf, obwohl die Technik nicht wirklich zur gewünschten Lösung passt? Oder es auch einfachere, bessere Ansätze gäbe? - 📹 Die Technik hinter ChatGPT
 Der Digital Learning Hub organisierte 3 Impuls-Workshops zum Einsatz von ChatGPT in der Sekundarstufe II. Im dritten Teil präsentierte ich die Technik hinter ChatGPT. In der halben Stunde Vortrag werden… 📹 Die Technik hinter ChatGPT weiterlesen
Der Digital Learning Hub organisierte 3 Impuls-Workshops zum Einsatz von ChatGPT in der Sekundarstufe II. Im dritten Teil präsentierte ich die Technik hinter ChatGPT. In der halben Stunde Vortrag werden… 📹 Die Technik hinter ChatGPT weiterlesen - Ist ChatGPT für Ihre Anwendung ungefährlich?
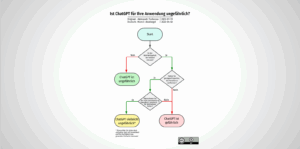 Ob man KI-Chatbots sicher einsetzen kann, hängt von der Anwendung ab. Aleksandr Tiulkanov hat deshalb ein Flussdiagramm als Entscheidungshilfe erstellt. Hier eine deutsche Übersetzung und ein paar Anmerkungen zum Korrekturlesen… Ist ChatGPT für Ihre Anwendung ungefährlich? weiterlesen
Ob man KI-Chatbots sicher einsetzen kann, hängt von der Anwendung ab. Aleksandr Tiulkanov hat deshalb ein Flussdiagramm als Entscheidungshilfe erstellt. Hier eine deutsche Übersetzung und ein paar Anmerkungen zum Korrekturlesen… Ist ChatGPT für Ihre Anwendung ungefährlich? weiterlesen - Wie funktioniert ChatGPT?
 ChatGPT ist wohl das zur Zeit mächtigste Künstliche-Intelligenz-Sprachmodell. Wir schauen etwas hinter die Kulissen, wie das „large language model“ GPT-3 und das darauf aufsetzende ChatGPT funktionieren.
ChatGPT ist wohl das zur Zeit mächtigste Künstliche-Intelligenz-Sprachmodell. Wir schauen etwas hinter die Kulissen, wie das „large language model“ GPT-3 und das darauf aufsetzende ChatGPT funktionieren. - Die KI ChatGPT und die Herausforderungen für die Gesellschaft
 Was lange währt, wird endlich, äh, published. Mein neuer DNIP-Artikel zu ChatGPT ist online, in drei Teilen:
Was lange währt, wird endlich, äh, published. Mein neuer DNIP-Artikel zu ChatGPT ist online, in drei Teilen: - Identifikation von KI-Kunst
 KI-Kunst ist auf dem Vormarsch, sowohl was die Qualität als auch die Quantität betrifft. Es liegt (leider) in der menschlichen Natur, einiges davon als „echte“, menschgeschaffene Kunst zu vermarkten. Hier… Identifikation von KI-Kunst weiterlesen
KI-Kunst ist auf dem Vormarsch, sowohl was die Qualität als auch die Quantität betrifft. Es liegt (leider) in der menschlichen Natur, einiges davon als „echte“, menschgeschaffene Kunst zu vermarkten. Hier… Identifikation von KI-Kunst weiterlesen - Die Lieblingsfragen von ChatGPT
 Entmutigt durch die vielen Antworten von ChatGPT, es könne mir auf diese oder jene Frage keine Antwort geben, weil es nur ein von OpenAI trainiertes Sprachmodell sei, versuchte ich, ChatGPT… Die Lieblingsfragen von ChatGPT weiterlesen
Entmutigt durch die vielen Antworten von ChatGPT, es könne mir auf diese oder jene Frage keine Antwort geben, weil es nur ein von OpenAI trainiertes Sprachmodell sei, versuchte ich, ChatGPT… Die Lieblingsfragen von ChatGPT weiterlesen - Wie funktioniert Künstliche Intelligenz?
 Am vergangenen Mittwoch habe ich im Rahmen der Volkshochschule Stein am Rhein einen Überblick über die Mächtigkeit, aber auch die teilweise Ohnmächtigkeit der Künstlichen Intelligenz gegeben. Das zahlreich anwesende Publikum… Wie funktioniert Künstliche Intelligenz? weiterlesen
Am vergangenen Mittwoch habe ich im Rahmen der Volkshochschule Stein am Rhein einen Überblick über die Mächtigkeit, aber auch die teilweise Ohnmächtigkeit der Künstlichen Intelligenz gegeben. Das zahlreich anwesende Publikum… Wie funktioniert Künstliche Intelligenz? weiterlesen - Künstliche Intelligenz — und jetzt?
 Am 16. November 2022 halte ich einen öffentlichen Vortrag zu künstlicher Intelligenz an der VHS Stein am Rhein. Sie sind herzlich eingeladen. Künstliche Intelligenz ist derzeit in aller Munde und… Künstliche Intelligenz — und jetzt? weiterlesen
Am 16. November 2022 halte ich einen öffentlichen Vortrag zu künstlicher Intelligenz an der VHS Stein am Rhein. Sie sind herzlich eingeladen. Künstliche Intelligenz ist derzeit in aller Munde und… Künstliche Intelligenz — und jetzt? weiterlesen - Reproduzierbare KI: Ein Selbstversuch
 Im NZZ Folio vom 6. September 2022 beschrieb Reto U. Schneider u.a., wie er mit DALL•E 2 Bilder erstellte. Die Bilder waren alle sehr eindrücklich. Ich fragte mich allerdings, wie viele… Reproduzierbare KI: Ein Selbstversuch weiterlesen
Im NZZ Folio vom 6. September 2022 beschrieb Reto U. Schneider u.a., wie er mit DALL•E 2 Bilder erstellte. Die Bilder waren alle sehr eindrücklich. Ich fragte mich allerdings, wie viele… Reproduzierbare KI: Ein Selbstversuch weiterlesen - Machine Learning: Künstliche Faultier-Intelligenz
 Machine Learning („ML“) wird als Wundermittel angepriesen um die Menschheit von fast allen repetitiven Verarbeitungsaufgaben zu entlasten: Von der automatischen Klassifizierung von Strassenschilden über medizinische Auswertungen von Gewebeproben bis zur… Machine Learning: Künstliche Faultier-Intelligenz weiterlesen
Machine Learning („ML“) wird als Wundermittel angepriesen um die Menschheit von fast allen repetitiven Verarbeitungsaufgaben zu entlasten: Von der automatischen Klassifizierung von Strassenschilden über medizinische Auswertungen von Gewebeproben bis zur… Machine Learning: Künstliche Faultier-Intelligenz weiterlesen





Schreibe einen Kommentar